
As a sequel of my previous post, I’m going to talk a little bit about another technique used in phishing that I encountered recently. This technique is HTML smuggling. This method is not new, but it definitely appears in more and more attacks, including phishing scenarios. This is why it is so important to know about the ins and outs of this approach.

List of the three methods I’m showing in this 3 episode-long series:
- Remote template injection
- HTML smuggling in attachment or link < - - You are here.
- Clickjacking in attached HTML
As I mentioned, it is not a new way to attack somebody. However, for me, last year (2020) was the first time I saw this attack in practice during a phishing investigation. In 2020, there was also an attack campaign called ‘Duri’ that utilized this technique. If you are interested, look it up.
HTML smuggling
So, what is HTML smuggling? HTML smuggling is a technique used to create malicious files on the host computer by the browser based on the content of an HTML file instead of forwarding/downloading a malware directly. HTML smuggling can be used to bypass perimeter security and on-the-wire detection by hiding the malicious file as encoded “string” in an HTML page.
Most of the perimeter/on-the-wire security solutions are looking for patterns in the file. In case of HTML smuggling, the malicious file is put together in the browser, so detecting this hidden code is difficult. Even detecting HTML smuggling itself can be hard due to obfuscation in the code.
What are the methods one can use?
There are two inherently different ways of smuggling I encountered last year (2020) during phishing investigations. As HTML smuggling in general, both solutions store the data in the html file and provides a way to ‘download’ it without additional request towards the server. Also, each solution is based on the HTML5 download attribute (not mandatory though but helps). The difference is in the technology they use.
Javascript Blob
The first solution is based on JS Blobs and this is the one I see more frequently. A Blob is an immutable object that represents raw data. You can find more information about the Blobs on the previous link. The relevant attribute here is that with the help of Blobs we can store and our files in the HTML code and put it together in the browser instead of sending file requests to the webserver .
I used the following two sources to create my html page:
- https://gist.github.com/darmie/e39373ee0a0f62715f3d2381bc1f0974
- https://developer.mozilla.org/en-US/docs/Web/API/Blob
To store your file, first you need to encode it to base64. You can do with the following code in Powershell:
$base64string = [Convert]::ToBase64String([IO.File]::ReadAllBytes($FileName))
Then replace the values in the html page. The fileName variable contains the name you want the file to be downloaded by default with. The base64_encoded_file variable stores the base64-encoded file.
<html>
<body>
<script>
var fileName = <>
var base64_encoded_file = <>
function _base64ToArrayBuffer(base64,mimeType) {
var binary_string = window.atob(base64);
var len = binary_string.length;
var bytes = new Uint8Array( len );
for (var i = 0; i < len; i++) {
bytes[i] = binary_string.charCodeAt(i);
}
return URL.createObjectURL(new Blob([bytes], {type: mimeType}))
}
var url = _base64ToArrayBuffer(base64_encoded_file,'octet/stream')
const link = document.createElement('a');
document.body.appendChild(link);
link.href = url;
link.download = fileName;
link.innerText = 'Download';
</script>
</body>
</html> After this, clicking on the link starts the Download.
DataURL
The other method to implement an HTML Smuggling solution is by the usage of DataURLs. With this solution you can stay completely javascript-free. The goal of the DataURL is to provide a way to embed smaller files into an HTML document.
I said, it is for smaller files, but actually, the limitation is not too strict. The max length of a DataURL is defined by the max URL length in the browser. For example, in Opera, this size is 65535 characters. This is not enough to transfer FHD movies this way, but big enough for a malware dropper or a reverse shell.
It is also a way simpler solution than the previous, JS-based one. Here is the syntax:
- “data:”: this fix string
- [<mediatype>] : MimeType
- [;base64] : the “;base64” tag if our data is base64 encoded
- ,: a comma that separates the data from the control information
- <data> : the data itself in base64 encoded format (in my case base64 encoded)
<html>
<body>
<a href="data:text/x-powershell;base64,aXBjb25maWcNCmhvc3RuYW1l"
download="test.ps1">
Download
</a>
</body>
</html>Here is a simple HTML file that is going to show a download button when opened. By clicking on the Download button a PowerShell script can be downloaded to the machine that executes ipconfig and hostname commands. The download anchor defines the filename and that you want to download the file by clicking the button.
During my test, nothing happened on Chrome when I removed the download anchor. On the other hand, Firefox could still download the file, but by default it had a random filename and no extension.
You can combine it with JavaScript to add some functions or to try to obfuscate it, or you can use it without any scripts, but in this case, it is going to be more limited obviously.
Why is it used by attackers
HTML smuggling is a really good addition to phishing attacks. With the help of it, an attacker can evade some detections and logging mechanism. The reason why it can bypass some of these solutions is that this way the files are “injected” into a HTML document. And most of the security solutions are simply not prepared to detect this.
On the other hand, it has some drawbacks. For one, it needs user interaction. The browser can put together the file, but the user must approve the download (except if the automatic download without confirmation is configured). Even if the file is downloaded it still has to be executed by another entity. It can be the user (so interaction is needed again), or another script, which means the attacker already had to compromise the machine.
However, frequently these cons are not relevant. The attacker can easily rely on the user, this is why phishing attacks are so convenient.
There are two methods that I have encountered during my phishing investigation in regards of HTML smuggling. In the first solution, the email contains a link that points to an external webpage (sometimes through a redirection chain) with HTML smuggling technique in it. This is the more frequent method. In the other case, an HTML file is attached to the e-mail, so the user doesn’t have to open any external site at all.
In both scenario the benefit is that the malicious content is not going to travel as usual. A malignant code is hidden in the HTML content. This way multiple security defenses can be bypassed.
First, take a look at how a normal file download happens. In the example on the picture below the user opens a website and then initiates an exe file download:
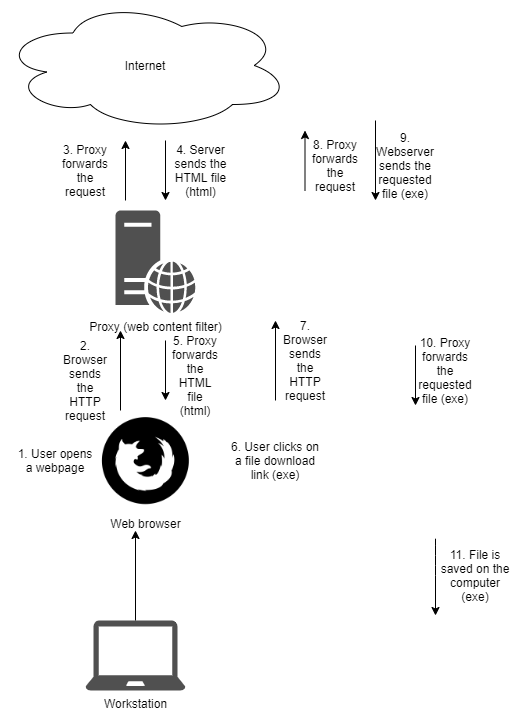
- First the user opens a normal webpage. This can be a user typing the URL, or it can be initiated from an ordinary phishing e-mail with a link in it.
- The browser sends the HTTP request to the website. If a proxy is in place, then this traffic will go through the proxy.
- The proxy checks the requested URL. A lot of proxy solutions have the capability to check the reputation of a domain. If it is deemed to be malicious, the communication stops here, otherwise, the proxy forwards the traffic to the webserver.
- The server sends back the requested resource. In my example this is just a normal HTML page.
- The proxy checks the response. Various filtering can be done at this point. The proxy can block the download of different files, filetypes. Also, the proxy can have a built-in sandbox to test the file. HTML files are usually let through the proxy and they are not tested in sandboxes.
- The page arrives to the browser. The user can decide at this point that one of the files, shown in the browser is interesting, so a file download can be started. In this example, the file is an exe.
- The browser sends a file download request towards the webserver.
- The proxy can do the same thing as before, nothing new here.
- The webserver sends the requested exe file to the proxy.
- When the proxy gets the file, it can evaluate it. If exe download is prohibited in the network, this file won’t reach the user’s machine. The proxy can check whether the file is a known bad file. Also, it can decide to send the file to a sandbox for testing. This is a key point here. At this point, the proxy knows that the file is an executable, and it can decide about the forwarding based on this information. Also, network taps can detect this exe file and they can also block its download if they think it is malicious.
- If nothing blocks the file, it can successfully reach its destination.
The most important part here is point 10. This will be the biggest difference between a normal download and an HTML smuggling. In case of a normal download the exe file is easy to detect, easy to evaluate (check hash, execute in sandbox, collect header information) and easy to act on. In case of smuggling, the file never travels on the wire in an un-encoded way, and it is always embedded in another (HTML) file.
Link in the e-mail method:
The first smuggling technique is the one I encountered more frequently. In this situation, the attacker puts a link into an e-mail. The link points to an external site that contains the smuggled file (exe file on the image). In this case, the malicious content does not go through the e-mail (security) gateway, but it goes through the proxy (in a hidden form).
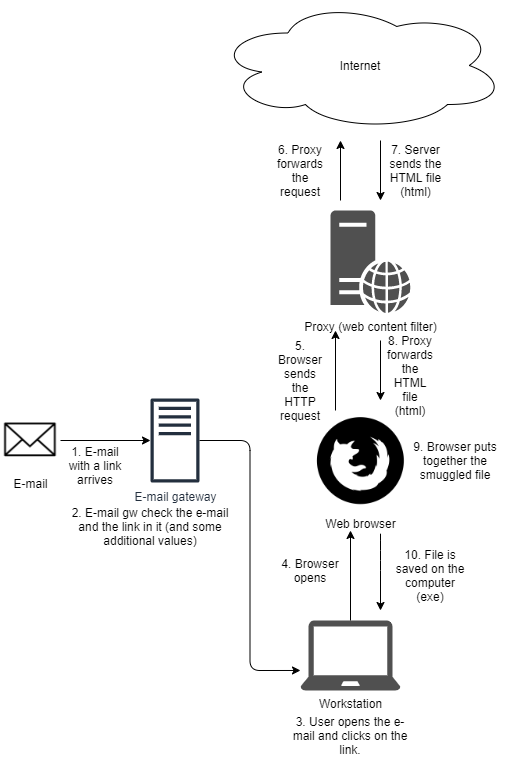
- An e-mail with a link in it arrives.
- The e-mail gateway checks the e-mail. There are various techniques to detect a phishing e-mail, but in this scenario, I assume the gateway won’t block the e-mail because there is nothing malicious in it. (Also, we all know that a lot of phishing flies under the radar.)
- The user clicks on the link in the e-mail.
- Default browser opens up.
- Browser sends the HTTP request to the external site that stores (or generates) the HTML document.
- The proxy does the necessary checks, but if the URL is not blocked, the request is forwarded to the website.
- Server sends back the HTML page and the exe file hidden in it. The exe file is stored as a “string” in the document. It is part of the HTML content at this point.
- The proxy checks the response which in this case is only an HTML file. HTML files are not blocked on proxies. Also, HTML files are not forwarded to sandbox solutions most of the time (never). The hidden malicious content is practically impossible to be detected here. Other network solutions can also take a look on the content of the file and they can potentially recognize the HTML smuggling technique (the technique itself, but not the malignant hidden file). But we’ll deal with this a little bit later. Let’s just say the proxy forwards the HTML file to the browser.
- The browser puts together the file from the string and initiates a download.
- The file is saved on the computer.
As one can see, an e-mail security solution can’t do too much in this case. The e-mail itself is not malicious, and the link in it can be a legitimate link.
The proxy can look at the HTML file, but HTML files are rarely processed thoroughly by security solutions. Most of the time these files are simply allowed. IDS solutions also tend to rely on the file extension / magic bytes, so an encoded string in a file is hard to be picked up by them. But processing Base64 encoded executables are not easy at this level. However, one can create a pattern matching solution to detect some HTML smuggling stuff. Again, I’m going to mention this a little bit later.
HTML attachment in the e-mail method
An HTML file that contains the smuggled file is attached to an e-mail.
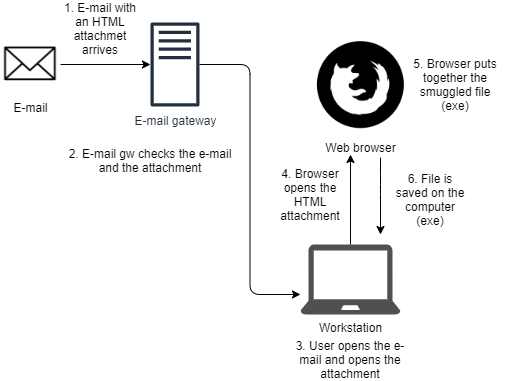
- An e-mail with an HTML attachment in it arrives.
- The e-mail gateway checks whether HTML documents are allowed or not. If not, it can block the e-mail or remove the attachment. Also, a deeper investigation can be done. However, I have never seen any e-mail security solution that could detect HTML smuggling (not even when malicious code was smuggled) with static or dynamic analysis.
- User opens the HTML attachment.
- Browser opens and loads the HTML document.
- The browser processes the content of the HTML file, processes the smuggled file and provides it for download to the user.
- File is saved to the computer. For this step either the user’s approval is needed or download without confirmation should be turned on.
This method is useful, because this way the malicious code does not travel through any proxy at all, not even in embedded way. Also, e-mails are frequently not touched by network IDS/IPS solutions. So, if an attacker can bypass the e-mail security gateway, then there won’t be any other challenge on the wire.
Prevention \ Detection
In case of HTML smuggling, there are two things you can try to detect. You either focus on the HTML smuggling technique itself or you try to catch the hidden malicious code. It is important to point out that the above explained techniques are used by legitimate sites too.
I wanted to find out how many sites use these techniques and how many benign files on an average machine are created by these. I checked less than 15 machines, so the sample is not representative. Based on this research (and this research only) an average 1 year old machine has 3-4 files on it created by HTML smuggling (not necessary in a malignant way). These were the files I found on the machines, but there could be more which were removed by the users already and I did not have information about. 3-4 files don’t look too many, but in a company with 10-20k machines, triggering (if possible) on every HTML smuggled file would have caused more than 100k alerts over the course of 1 year.
However, when you suspect a machine is infected, then investigating an additional 3-4 files is not a big deal. Therefore, identifying potentially HTML smuggled files are still a good idea.
So, how to detect or defend against HTML smuggling? There are some basic recommendations, like use up-to-date softwares, defense-in-depth, etc which I do not want to mention here. The reason behind this is simply that these recommendations are true for everything. Let’s focus on more specific stuff here.
Prevention
1. Block JavaScript execution
There is no method I could mention about defending specifically against HTML smuggling in general. Disabling JavaScript can be a solution against one type of smuggling, but let’s face it, disabling JavaScript in an enterprise environment is practically infeasible. If it can be done in your environment for some reason, then well… do it. And in that case, only the DataURL method must be detected by you, which is after blocking JavaScript is not that hard by pattern matching.
2. Block HTML file as attachments in e-mails
One of the types of HTML smuggling uses HTML files as attachments. Unfortunately, this is again something, that can be normal in lots of environments. I can actually see an increase in legitimate, business-related e-mail with HTML attachments in them. On the other hand, I can also see more and more phishing e-mails with HTML attachments.
If you can block these attachments without having any business-impact, then you covered one of the most used HTML smuggling methods. Now you only have to focus on links in the e-mails.
As you can see in regard to these first two detection methods, they do not cover every type of HTML smuggling. Even if you could use both of these solutions, some HTML smuggling-based phishing could still go through your security systems. And this is the best-case scenario. In the worst-case scenario, you can’t even use these solutions, because they are not viable in most modern enterprise environments.
3. Microsoft Defender Application Guard
Microsoft Defender Application Guard is a solution for Windows to isolate various applications if they try to use resources from an untrusted source. Application Guard comes in two different flavors. Application Guard for Edge helps to isolate enterprise-defined untrusted (or not specifically trusted) sites, protecting your company while your employees browse the Internet. Application Guard does this by opening the site in an isolated Hyper-V-enabled container. Also, it does work with Firefox and Chrome browsers too.
The other version of it is Application Guard for Office. This solution helps to defend trusted resources from files from untrusted sources. It does this by opening the untrusted Word, Excel, PowerPoint document in a container. This is less relevant in regard to HTML smuggling, so I am not going to talk about it.
Application Guard for Edge
This solution helps defend your systems by opening untrusted links in an isolated virtual environment. This way a not defined URL (or a known bad URL) is not able to do any harm to the host and the user cannot download malicious files from this location (or he/she can, but it is going to be stored in the isolated environment).
If a link arrives in an e-mail and the given URL is not whitelisted, then it will open in an isolated Edge session. If the URL is in the isolated environment, then every file download is also going to happen in this environment. So, the smuggled file can only be downloaded inside the container and where it cannot do any harm (normally).
Drawbacks:
- To make it really secure, you have to use whitelisting and ‘untrust’ everything else. In a big company, this can mean a huge amount of load on administrators who manage this list because users will request exceptions constantly.
- Attachments arriving via e-mail are opened in the browser as local files. Thus, these files are not going to be handled as untrusted domains, they won’t trigger the Application Guard. So, they won’t be opened in an isolated browser. Therefore, HTML smuggling via an HTML attachment can still be successful.
- It can be slow, especially during the initial container creation phase.
Here is a little gif that shows how Application Guard for Edge works:
- First, I opened google.com, which was already defined as a trusted website.
- Then, I opened my blog, which is not defined as a trusted website.
- Since it is not trusted, Application Guard creates an isolated environment to load the URL in it. This takes a few seconds.
- The URL is opened in the container. This is shown by a little icon in Edge.
Detection
1. Pattern matching
DataURL can be easy to detect if it does not utilize any JavaScript. In this case, a simple pattern matching tool can detect the “data:” string in the HTML file. Also, DataURL has a specific syntax that also can be detected (see above). You can detect this by using an IDS or any simple YARA tool. One such tool is LaikaBOSS (https://github.com/lmco/laikaboss).
LaikaBOSS is a file-centric IDS that can be really effective in case of downloaded files (HTML files) or even with e-mail attachments. I worked at a company where we used this tool, and I really liked the threats it detected for us. It can be used on a huge amount of data, it scales well, so even in a big environment, it can be utilized.
On the other hand, if JavaScript is used then the code can be heavily obfuscated. In this case, pattern matching tends to be less effective. One can try to detect obfuscated code with different methods (eg. frequency analysis), but this detection is not HTML smuggling specific.
2. Browser created file without network traffic
One of the benefits of this technique is that an attacker can bypass perimeter security. One of the tools an HTML smuggled file can hide from is a webproxy. When HTML smuggling is used, the file is technically created in the browser, while in a normal file download scenario it is requested from the web server, so the downloaded file goes through the proxy. We could detect HTML smuggling by focusing on this difference between a normal file download and an HTML smuggling-based file creation.
One way to detect HTML smuggling is to correlate two types of activities:
- File creation on the host by a user and by any browser process.
- The lack of proxy logs with the same filename, same user around the same time.
At first, this query seems heavy, but it is easy to whitelist some folders and to heavily decrease the number of possible logs. In case of HTML smuggling, the user has to approve the download. The user will either just click on the okay button and download the file to the default download directory or specify a location. However, a user rarely downloads anything intentionally into Temp or any System folders, so these can be removed from the rule. And this is just a simple example.
Drawbacks:
- Lots of traffic won’t go through the proxy by default. Like companies can configure their network in a way that internal sites won’t be reached via proxy. In this case, a file is generated by the browser, but there is no proxy log. And this will happen frequently, so no alert should be created based on this logic.
- Users can also bypass the proxy in some cases, so there won’t be any proxy logs at all.
- One can open local files in the browser and then save it as a new file. This is a file creation by the browser but again, no proxy logs.
3. Sandboxing
You could send the HTML file to a sandbox and open it there with a browser. An HTML file without internet access shouldn’t create anything on a machine besides some temp files. Theoretically, you could send an HTML file to a sandbox without network access and if a file is created there (let’s say in the default download directory) it should raise an alarm.
Unfortunately, my experience shows HTML files are never sandboxed. They can be checked with static analysis (see LaikaBOSS above), but dynamic analyses would take way more time and would slow down the network significantly.
Drawbacks:
- Not feasible most of the time because opening every html file before forwarding it to the user is too heavy.
- Only works if the page is configured to initiate the file download automatically. If the user has to click on a button for this, then it can’t be detected this way. In my example codes above, I did not use automatic download. So, right now, I would say this solution is only theoretical. And can only work in extremely closed-down networks.
4. ‘Unique’ Zone.Identifier values:
When a file is created by a browser (or a lot of other tools) an Alternate Data Stream called Zone.Identifier is attached to it. The value the Zone.Identifier contains depends on the type of software you use for downloading, but also on the site you download the file from.
I’m not going to go into detail about Zone.Identifier, you can find more information here. But let’s see what it shows in case of HTML smuggling. When you save a file created by HTML smuggling, it is created by your browser. The HTML file itself can’t be detected this way, but the hidden file in the HTML document which are created at the end can have a Zone.Identifier value.
The Zone.Identifier for a file created by HTML smuggling will be the following (tested on Edge (new), Chrome, Firefox):
[ZoneTransfer]
ZoneId=3
HostUrl=about:internet
While a file downloaded the usual way will have different information, like this (but this varies from browser to browser):
[ZoneTransfer]
ZoneId=3
ReferrerUrl=https://www.sans.org/security-resources/posters/windows-forensic-analysis/170/download
HostUrl=https://www.sans.org/security-resources/posters/windows-forensic-analysis/170/download
Drawbacks:
- Only works on Windows (NTFS) and even then, it is software-dependent.
- Can be noisy. A lot of online creators and editor tools use it, like draw.io. If these things are not allowed at your company, you can block them, and you can significantly decrease the FP detection by this logic.
- As you can see on the link above, this specific Zone.Identifier is not unique for HTML smuggling. It appears in case the file was downloaded with various torrent applications, but also files downloaded from WhatsApp web contain this value.
This detection again, not a completely reliable one, so implementing it as an alerting rule is maybe not a good idea. Also, it wouldn’t be easy, because triggering based on Data Streams is not trivial.
If you are interested which of your files have the same Zone.Identifier, you can check it with this PowerShell code:
$ErrorActionPreference = "silentlycontinue"
Get-ChildItem -Recurse -Path * | ForEach {
$ZI = Get-Content -Path $_.Name -Stream Zone.Identifier -ErrorAction SilentlyContinue;
if ($ZI -match "HostUrl=about:internet")
{Write-Host $_.Name "`n" $ZI}
}This script returned with 8 files on my machine. Identifying which file was created by HTML smuggling and which was not is normally impossible. I was lucky though because I knew where the files were downloaded from. So, I could just check these sites (some of them were internal) to see whether they use Blobs or DataURLs. 2 of them did not use any of these methods and the match was just a coincidence. 3 of them used DataURLs, they were downloaded from an online editor tool, and the remaining ones were created by my HTML smuggling tests.
Update 12/04/2021 - a 5th artifact
5. Chrome artifacts
After I published this post I found some additional browser forensic artifacts which can help us identify HTML smuggling. Without going into details, I used Hindsight to collect Chrome-related artifacts. As you possibly know Chrome stores the origin of the downloaded files. But when the source is a JavaScript blob or a DataURL, then this information will be presented as source.
In case the HTML file was opened locally:

It does not show us the file/url from which the smuggled file was downloaded.
On the other hand, when the HTML page was opened on a remote server, I could see the URL. However, this is only the situation in case of Blobs, DataURL still doesn’t show the URL.

Potentially, one can find other ways to identify HTML smuggling via forensic artifacts. But again, be aware, this does not mean the file is malicious. Most of the files created via blobs were legitimate in my case.
So far, this method seems to be the most reliable one. In case of remote HTML file and Blob usage we can even find the real URL. Also in case of DataURL we can re-create the whole file. This information can be useful in certain cases. Please be aware, I found this after I finished my post, so other comments regarding the detections do not apply to this finding.
End of the update 12/04/2021
Detection in General
Previously I showed a few methods that could be used to detect HTML smuggling or files generated via smuggling. However, none of them are too reliable. Either they can miss smuggling, they can detect a lot of False Positives, or simply they are infeasible most of the time. So, they are not good as detection rules. But this does not mean we can’t use them at all.
First, even though they are not reliable separately, they can still be useful if we utilize more of them to detect smuggling. For example, let’s say a user opened an HTML file from the internet and we detected heavy obfuscation in the file. Obfuscation can be used by legitimate sites, so in itself, this is not reliable. But, a few seconds after this we also detect the previously introduced Zone.Identifier value on the machine of the same user. These two detections together can be a more reliable sign of a smuggled file.
Second, we can fine-tune our detections by focusing only on specific file extensions. We can exclude the file types we think are not suspicious for us. Or we can focus on the file types which are frequently seen during HTML smuggling activities. In this case zip, exe, bat files would be the files I would cover immediately since these are the ones, I have encountered most frequently over the last 1-1,5 years. Also, most of the sites which legitimately use HTML smuggling create image files (based on my experiments), so these are the ones I would whitelist first.
And the third reason is that even though they are not good as detections they can provide valuable forensic information. On my machine -I use for work and which was installed 4 months ago- I found 8 files with the related Zone.Identifier in them. In case of a forensic investigation, marking these files can be useful.
Various forensic tools provide a list of suspicious files to the investigator. These tools collect and check a lot of information about the files found on the machine. They check the reputation of the files based on their hash, they can detect tampered timestamps, potential masqueraded files, and so on. But none of them - I used so far – marked a potential HTML smuggled file as suspicious. This information could be a good addition and could help an investigation.
The End
Overall, the prevention and detection of HTML smuggling is a difficult task nowadays. Even though the introduced techniques are not reliable to be used constantly, they can be utilized during a forensic investigation to identify files of interest.