
When you investigate a malicious site opening or malicious file download, oftentimes you want to find out how your user got there. Checking the referrer information in proxy logs is one of the most trivial things to do if you want to identify the root cause, the initial site. Unfortunately, there are ways for an attacker to create a site that will alter or hide the referrer information. If the logs do not have the required referrer information and you are not aware that they can be hidden, you can incorrectly assume that there was no referrer at all. So, I created this blog post to explain some of the methods I’ve encountered recently (and slowed down my investigation).

Lately, I’ve had an incident in which the attacker used multiple methods to make the identification of the original malicious site difficult. During this incident, I got an alert that some users opened a malicious site (in reality the alert was a little bit more complicated) so I wanted to find out why and how the users opened the given site.
The referrer information in the proxy logs I investigated was empty. At the time, I did not know this information can be removed by modifying the referrer-policy header value. I was stuck for a really long time, as I tried to rule out every option which could cause the opening of these malicious sites. As I investigated some of the sites opened by the users and checked their source code I found the no-referrer meta tag. As I realized this information can be hidden, I read about other techniques, and I found all the methods the attacker used to hide information from me to make my investigation harder.
Techniques to hide referrer information
In my investigation I discovered three different techniques which were used by the attacker to make the finding of the initial domain harder:
- 30X Redirection: When you redirect your visitor from site A to site B, in the request towards site B the referrer is not going to be site A itself, but the referrer of site A (if there is any). Normally, one could assume that after redirecting somebody from site A to site B, the referrer is going to be site A, but this is not the case. This can be confusing in case of an investigation.
- HTML refresh redirection: One can hide the referrer information by using the refresh meta tag in an HTML site. However, whether the referrer is going to be shown or not depends on the browser. In case of refresh redirection, some browsers create a request with the referrer information in it while other browsers remove this information regardless of the Referrer-Policy.
- Referrer HTML meta tag: With this meta tag one can control what information should be included in an HTTP request. It is possible to include the full origin, path, and query information, only the origin or removing all referrer information.
30X Redirection
You can configure a site to redirect a user to a different site (different domain or path) upon visiting your page. This can be done by a simple PHP code, which means it is easy to create a site that dynamically redirects users, so not everybody is going to be redirected.
I tested HTTP 301, 302, 304 redirections. I assume it works in case of other types of 30X redirections too, but again, only those were tested by me.
In my test scenario I created an HTML page (initial.html). I put a link into this page that pointed to siteA.php. This siteA.php had a small code in it to redirect every visitor to siteB.html with status code 302. This is the related php code for redirection:
<?php
header("Location: http://127.0.0.1:80/index.html",true, 302);
?>
So I opened initial.html, clicked on the link which pointed to siteA.php. But opening siteA.php 302 redirected me to siteB.php. On the first picture one can see the HTTP status codes (from Chrome):

The referrer in the request to open siteA.php is http://127.0.0.1/initial.html which is what I expected.
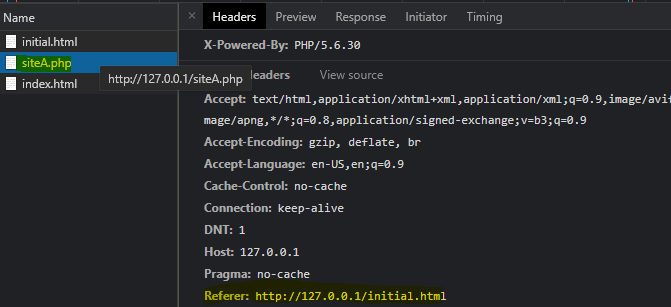
On the other hand, one can see on the next picture that the referrer in the request to open siteB.html is also http://127.0.0.1/initial.html. So, based on the referrer information it looks like the site was opened directly from initial.html instead of from siteA.php.
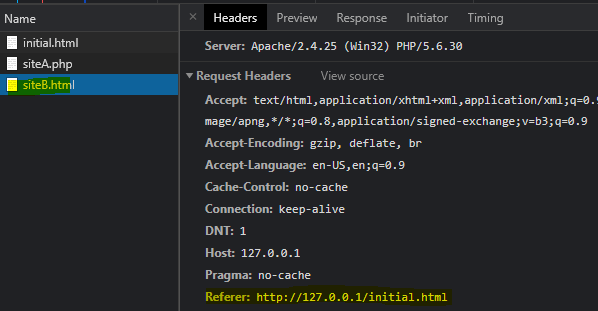
This behavior hides the fact that initial.html and siteB.html do not have any direct connection, so checking the source code of initial.html won’t show any reference to siteB. Also, since the redirection can be dynamically executed, one user may be redirected to the given page, but later on an analyst does not, which makes the investigation even harder.
Reasons to use it by an attacker
- An attacker can make the investigation harder by removing one crucial site from the referrer chain. By backtracking the referrer chain an analyst can miss a domain that is a potentially malicious one. Also, by dynamically executing the redirection even by opening the given site the analyst won’t be able to connect this site (siteA) to the infection.
- The attacker can keep one domain safe (initial.html). Let’s say the attacker has a watering-hole domain. A site that seems clean has a high SEO score, so users browsing the internet will frequently find it. A user can use Google to find some information and the search engine shows this watering-hole domain to the user. The user opens it, and he is redirected to a malicious site. The redirection is dynamic, so it is hard to detect by security scanners. Because of this, the site looks like a clean site, it won’t be blocked, and the search engines will list it constantly. Also, it will be hard to identify internally, because it will appear the referrer of the malicious site is Google (or any search engine) and not the watering-hole domain, so by missing the domain the analyst won’t block it internally. The attacker can simply change the malicious target and then keep working with the initial heavily visited site.
Tested on:
- Google Chrome 90.0.4430.85
- Firefox 88.0
- Edge 90.0.818.49
HTML refresh redirection
One can also redirect a user to a different page by using the HTML meta tag with the http-equiv attribute. The usage of this type of redirection is discouraged but this does not mean it is not used, or especially that an attacker won’t use it. So, let’s see how it works.
I created some test files. The redirector.html file (see the code below) simply redirects the user to target.html site.
<html>
<head>
<meta http-equiv="refresh" content="0;url=http://127.0.0.1/target.html">
</head>
<body>
...
</body>
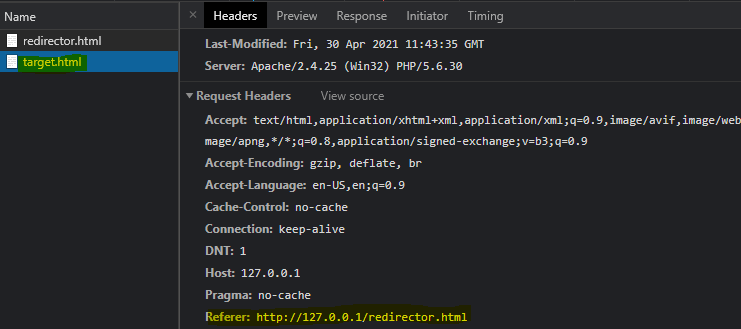
</html> Here, the separate browsers acts differently. While Chrome and Edge show that the referrer of target.html is redirector.html, Firefox do not have this information. This means if you open a site in Firefox and the site uses the http-equiv attribute for redirection then you won’t have the referrer information.
It is also important to point out that this is not really a redirection, all the attempts will be logged under HTTP status code 200 (at least if they are successful and not under 30X).
Opening the site in Chrome:
Opening the site in Firefox. As you can see there is no referrer information:
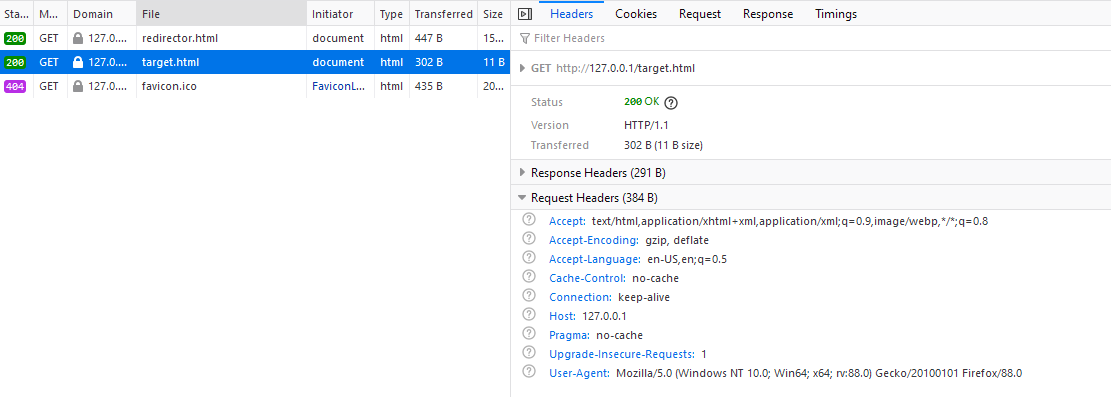
While this is not necessarily something an attacker would use to hide information, it is important to be aware of how different browsers can handle this type of refresh action. If you know which browser was used during the site opening, you know what information can be potentially missing. So if your user used Firefox and you don’t see a referrer it can be due to a http-equiv=“refresh” redirection.
Tested on:
- Google Chrome 90.0.4430.85 - Referrer is shown
- Firefox 88.0 - No referrer information
- Edge 90.0.818.49 - Referrer is shown
Referrer HTML meta tag
It is possible to configure the Referrer-Policy by using “referrer” HTML meta tag. You can find the possible policies and how they work on the link above. You can configure the site so it will send no referrer data, only the origin or the full origin, path, query information. An attacker can use this tag to hide the referrer information.
This is how you can configure the Referrer-Policy to not forward referrer information from an HTML document:
<meta name="referrer" content="no-referrer"> Or you can use a similar code from PHP:
header("Referrer-Policy: no-referrer");
So using the “no-referrer” policy one can remove the referrer information from the HTTP requests.
Why would an attacker use it
- It is possible to hide referrer information, so finding the real source of a browsing session is going to be harder. Frequently the only connection between 2 sites (based on proxy logs) is the referrer information, so losing this tidbit is hurtful. Also, if you are not aware of this option you can incorrectly think that there was no previous site, no referrer.
You can find the browser compatibility on THIS PAGE. According to the site most of the modern desktop browsers support Referrer-Policy.
The incident
I created this blogpost based on an alert I investigated recently. In this section, I’m explaining how the attacker used the above-mentioned techniques to hide its traces and to make my investigation harder.
The following steps were done by the users (or by the attacker’s sites):
- The users were searching for various topics on Google.
- Google showed the results to the users and one of these results was a site owned by the attacker. This site showed up for every user, but it wasn’t marked as malicious, and it wasn’t a newly registered site. When I checked the users’ browsing and executed the same searches I found the site on the 3-4th pages on Google.
- After opening this site, the users were redirected (302 redirection) to another site. Every user was forwarded to the same site. This site was marked as clean at the time of my investigation, but at tha time it was only registered a few days ago. With this step, the attacker hid the intermediary site and from the proxy logs, it looked like this site was opened directly from Google.
- Starting from this common site all the users were redirected through multiple different newly registered domains. All these domains contained the “no-referrer” meta tag, so no referrer information was shown in the proxy logs.
- In the end, all users were directed to the same common domain.
HTML refresh redirection (http-equiv) was also used on some of the sites, but our user did use Firefox, so this did not affect my logs at all.
As you can see, an investigation like this is not easy. Following the pages in forwarding order is not necessarily hard, especially if you have access to the sites. However, tracking them back one by one during an investigation is a bigger challenge. In this case, the attacker even used a redirection chaining (sending the users through a lot of domains), so there were a lot of sites to be checked.
Summary
During a similar investigation, you must be aware even if the value of the ‘Referrer’ is “None” it does not mean the user did not get to this site from another one. The referrer information can be hidden. Even having a referrer value does not mean the user really came from that site directly, it can be the result of a 30X redirection.