When you handle logs in a SIEM, times are really important. It doesn’t matter whether you investigate alerts, or you create a detection, having the proper times and knowing the different time-related fields can be critical. One of these time fields is the ingestion time value which tells you when an event became available in a SIEM for you to query. I’m showing you here how to create a detection and perform an investigation without missing any alerts.

There are 3 fields in Sentinel that are worth talking about when we discuss timing:
- TimeGenerated: this field shows the value of when the event was created on the source. When you configure a time range on the GUI you define this value. This is also the value you are going to use during most of your investigations.
- _TimeReceived: the time when the log reached the ingestion point. At this point, the data is not accessible yet, so this field can be used to calculate some delay information without involving delay by the SIEM.
- ingestion_time(): this function returns with the time of when the event was successfully parsed and indexed and became available for you to query.
The TimeGenerated value is important during the investigation because it tells you when an actual action was carried out and also tells you the ordering of the events. You want to detect a successful login after 15 failed ones (potential brute-force) this is the timestamp you want to use.
Still, there are a lot of SIEMs (or log stores) out there that do not give you the option to filter based on this value. There are even tools out there that try to define the order of the events based on the ingestion_time() field (obviously in other tools it is called differently but has the same functionality).
If ‘A’ event happens after ‘B’ event but they arrive in different orders, then these SIEMs are not going to provide us the good results when filtering based on event ordering. This is obviously a bad approach.
Problem
Sentinel uses the TimeGenerated field as its main time filter. When you use the Time Range filter on the GUI, you actually define a filter based on the TimeGenerated field.
When you create a rule, and you define “Lookup data from the last” time filter it is also translated to a subsequent TimeGenerated condition.
Even though TimeGenerated is the main time filter, you can use any other time-related field in your KQL queries.
However, this also introduces a small (or not that small) issue, namely, that you can accidentally miss some of the logs with your query because the events are not there yet when the search happens.
Microsoft already created a nice post detailing this issue and showing a good solution for it. Because of this article, I’m not going too deep with the explanation of the problem. So, to the gist.
The creation time of the log is ‘TimeGenerated’, the time you can start using the log is ‘ingestion_time()’ and the difference between the two is the ingestion delay. Every log has a greater than zero ingestion delay which varies based on a lot of different attributes.
When you create an Analytics Rule in Sentinel you have to define a TimeGenerated value (Lookup data from the last), and the query during its execution is going to check the logs with a TimeGenerated value greater than the defined one. For the sake of this example, let’s say that you defined the TimeGenerated value to be 4 hours.
If the log source you want to monitor with your rule has a 1-hour fix ingestion delay, then with your 4 hours configuration you will only be able to monitor the logs which were created in the first 3 hours of the 4-hour time window. But the logs created in the last hour will not yet be in the SIEM during the execution because of the ingestion delay.
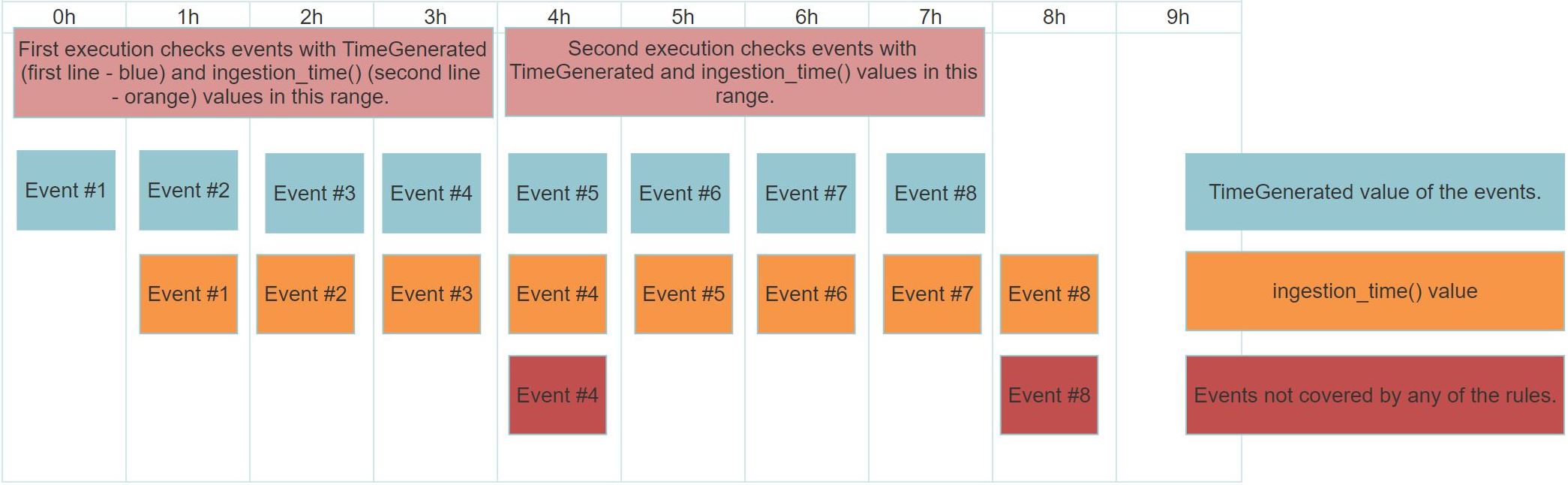
If you execute the same rule 4 hours from now, you still won’t cover the events that you missed before. Even though these logs are in the SIEM and they arrived in the time window of the second execution, they were created (TimeGenerated) more than 4 hours before the second execution. Thus, the TimeGenerated constraint filters them out. These are the events that are in the red boxes on the image.
Again, you can find a proper description about the problem and solution on MS’s site.
This also means if you do an investigation, you need to be aware of the ingestion delay. Unfortunately, in case of an IR activity, you can’t solve this problem. The only thing you can do is be aware of the ingestion delay and wait for the logs. Or if it is urgent, then try to pull the logs from the source directly. I worked in environments where the ingestion delay of some crucial logs was up to 3-4 days. This meant that sometimes we could not even start a proper investigation for days because of the missing logs.
In an example, the recommendation from MS is when you set the rule to run every 5 minutes and to lookup data from the last 7 minutes then use the following query:
|
|
This is indeed a working solution to ensure no logs are missed or processed twice. So, the question is how to define the ingestion delay.
Be aware, the query on MS’s site is not correct, it misses an ‘ago’ keyword.
Calculating ingestion delay
Based on the previous descriptions one can see that calculating ingestion delay is not hard at all. A simple query for this:
|
|

One can see on the image that the average delay is 14 minutes, but for example, the 99.99th percentile is already more than 3 days. This means 0.001% of our logs arrived after 3 days. So, 10 out of 1 million logs arrived with a huge latency.
Here you have to make a decision. Is losing 10 out of 1 million logs acceptable to you? Or are you okay with creating heavy rules that have to check the last 3 days of data instead of only covering the last 15 minutes? This latter decision can also introduce some duplicate detections you have to deal with. The decision is yours.
If you configure both the TimeGenerated and ingestion_time() filter in a query, don’t forget to always set the TimeGenerated higher than the ingestion_time(). An event is always created first and then after some processing and forwarding it becomes useful to you. If the two times are the same, then there will always be events you will overlook with your query.
I normally like to use the 99.999th percentile value, or if it is close to the maximum ingestion delay then I just use that one. But this is really up to you and your environment.
Now, that you know how to calculate the ingestion delay you still have to face some challenges:
- The ingestion delay can change over time: Once you introduce new log sources you can slow down your network or host that will result in a higher ingestion delay. Or you can improve your network to decrease the log forwarding time.
- Maybe you are a Security Provider with a lot of customers. Each one of them can have a different ingestion delay.
- Ingestion delay can also follow a seasonal pattern. For example, during the weekend when people are not working there can be less logs to forward and also more capacity to forward the logs. (My solution does not address this problem, but with a little bit of modification and creativity you can achieve this.)
Either way, hardcoding ingestion delay values into the rules and queries can’t provide optimal performance.
Dynamic ingestion delay in rules
The first part of the solution is to create a Watchlist and to store the delays in it.
A watchlist like this can be filled out by a Playbook dynamically. This Playbook can be executed in a scheduled manner, so the watchlist will have up-to-date data constantly. The Playbook I created calculates the 99.999th percentile ingestion_delay for each data table, adds a little bit of extra time to it and saves that value in the Watchlist. After this, I only have to query the Watchlist which is a really quick action. You can find the playbook on my gitlab repo. The code can change over time.
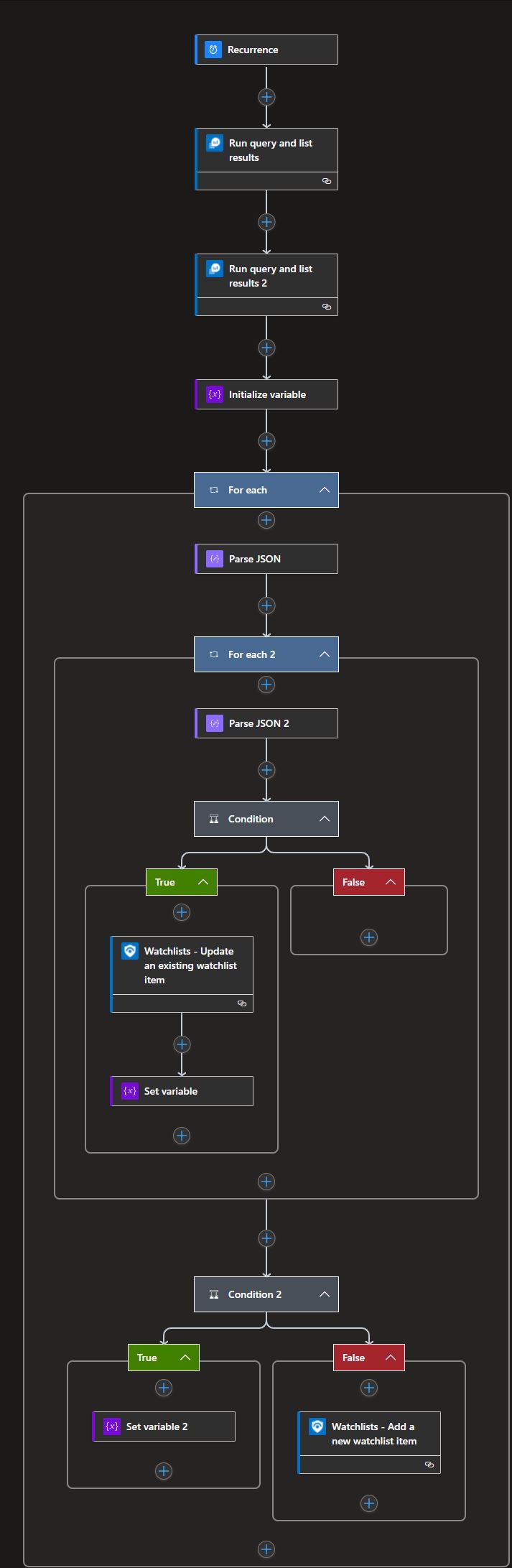
Core steps of the Playbook (the final Playbook in my repo can have different names for the blocks – see the image below):
- Run query and list results: Executes a query to calculate the ingestion delay for each table.
- Run query and list results 2: Collects the tables that are already on the Watchlist. This step is needed because we have limited Watchlist actions in a LogicApp.
- Condition: In the loops, I’m going through the results of the two Run query blocks. The first condition checks whether an entry (data table) already exists in the Watchlist or not. If it is there, I update the related value to the newly calculated ingestion delay.
- Condition 2: If the entry is not yet in the Watchlist then I create a new entry (data table) with the calculated ingestion delay.
The second step of the solution is to somehow use these values in a rule or query. To achieve this, you can use a user-defined function at the beginning of your query:
|
|
In this example, my watchlist is called “TimeIngestionDelay”. This Watchlist has two user-defined columns:
- DataTable: name of the Data Table
- TimeIngestionDelay: the ingestion delay value
You can call the function by providing the name of the data table which you want to get the ingestion delay value for. The function returns with the ingestion delay value.
And to show how to use it in a query let’s use the code I have already shown from MS’s site. You can see the changes in highlights.
|
|
So, we only need to add the function to the beginning and slightly change the definition of the ingestion_delay.
Some of the data tables can have events from different log sources. For example, CommonSecurityLog tends to store data from various network devices, like different firewalls or routers. These systems frequently have different ingestion delays. My Playbook and method do not take this into consideration.
We can just as easily modify Analytics rules. Even detections found on the Azure GitHub repository are easy to adapt to this methodology. One thing to pay attention to is the value you configure as “Lookup data from the last …” during rule creation. This setting acts as a time-based wrapper around your rule. If you define 1 hour in this field then it does not matter if you set a higher number in your query you will be able to only see 1 hour worth of logs.
So, be sure to set this value to a high number. Something, that is surely bigger than your ingestion delay. You don’t have to be afraid of slowing down your query, because if you implemented the above-mentioned method then in the first line the query immediately narrows the logs down to ingestion_delay + rule_look_back.
Bad practices
Some odd timing solutions I have seen in the past:
- Use the maximum of 14 days in all rules to ensure you do not miss anything. While this solution is good, because you really won’t miss anything, but at the same time your queries are going to be extremely inefficient.
- Using the same ingestion delay for all of the customers and log sources. This is possibly the worst option; you can still miss some events in addition to your rules being inefficient.
- Not considering ingestion delay at all. This is what I have seen at most of the companies. Well, at least this query can be quick. But that is not that difficult to achieve considering this way you ignore a lot of events.
You can use your rules to their fullest by using the constraints defined by Microsoft plus the dynamic ingestion delay calculation and method I suggested. This way you can be as effective as possible without missing any logs.