If you deploy Sentinel daily, you possibly have a step-by-step process you follow to maximize your efficiency. A process like this is needed to be effective and to be able the make your setup reliable and repeatable. Rule creation in Sentinel can be a part of the procedure and it often isn’t the last step. Rules can only be deployed in Sentinel if the table (data source) they are based on is already in Sentinel. Further steps which need specific rules to be ready can be halted in case of a missing table. I am going to show you how to handle this missing table impediment.

If your tasks are impeded by a preceding step, you can be in a pretty bad spot. You can just wait for the tables to be created. Sometimes this does not take too much time, but in other cases this can take weeks. Let’s say you have a log source that forwards logs to a Sentinel custom table via Logstash. This step will need a Logstash server setup, a network (firewall) configuration and potentially Logstash configuration on the system. At smaller companies these steps can be handled by different Service Providers which can really slow down the process.
You can also decide to ditch your process completely. This can make the whole engagement faster, but you risk missing some part of the configuration, possibly your steps need to be executed multiple times and overall, you are not going to be that reliable.
An example of this: let’s say you have a rule A which needs data table A to be available in Sentinel. Without table A you can’t test whether the rule works or not. Steps relying on rule A will be also halted. Your automation logic, that creates a ticket or sends an e-mail only when this rule triggers, can’t be tested. A Playbook can be there to automatically isolate a machine when this rule triggers, but without the rule you can’t test whether it works fine or not. You want to put together a documentation of the deployed rules and they MITRE classification to showcase it to your client. Without this rule your document either won’t be complete or it will contain incorrect information.
Even worse if you have complex correlation rules. Like rule C triggers if rule A triggers first and after this rule B triggers as well. In this case table A will not only block the steps that are based on rule A but also steps that are based on rule C.
Issues with deploying rules without data table
It does not matter whether you want to use the GUI, ARM templates or any other way to deploy rules you are going to have issues if the required data table is not in Sentinel yet. You are also going to have problems if the data table is there, but a field needed by the rule is missing.
If you try to create a rule on the GUI and the table or any of the fields are missing you will see this error:

If you try to use ARM template for deployment and the table is missing you get an error during deployment:
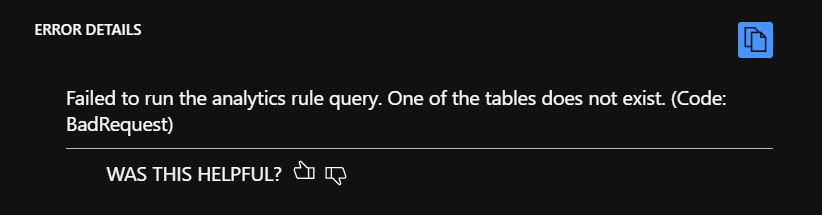
But this error only shows up if you want to deploy the rule in ’enabled’ state. If you change the ’enabled’ parameter to false, then the deployment is going to be successful. Obviously, the rule won’t work in ‘disabled’ state. After this you have to enable the rule yourself. But this step will result in an error:
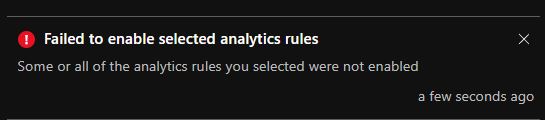
So, even though you can deploy a rule with missing tables, you won’t be able to enable it at the end.
The error message is different, but the overall behavior is the same for non-existent properties (fields). In case of a missing property, you can’t deploy the rule in ’enabled’ state, but you can deploy it in ‘disabled’ state. Also, after deployment you won’t be able to enable it (same error message) if the field is not available.
How to solve this
Missing data table and properties can cause us a problem, because we won’t be able to deploy rules. And this inconvenience can slow down or completely halt our deployment process. But this or that way we must move forward. Here are some options to overcome the limitation.
1. Don’t address the problem
Even though, this does not look like the way to go, this is what most of the companies do. Ignoring this problem is also somewhat a solution. You can just leave the given rules behind, deploy everything else and then handle the remaining steps when the requirements are met. You can still move forward, but as I stated before you are going to be potentially slow, less effective and unreliable.
This can be an option for you if you rarely do rule deployments, or rarely have to use custom logsources. Also, if you are small and you don’t have a strict process in place there is a chance you already use this nasty solution.
2. Deploy the rules in a disabled state
As I showed before, you can deploy any rule in a ‘disabled’ state, but you won’t be able to enable them until the necessary data table appears in Sentinel. (You will also need the used fields to be present in the logs). This can be a convenient solution if you only want to deploy rules but enabling them is not crucial. For example, if you want to create a document for your client to showcase the deployed rules and their MITRE coverage then this solution can be good enough for you.
Benefits:
- The rules are deployed in Sentinel which can be enough for some tasks.
Drawbacks:
- You have to manually enable the rules. In case of multiple missing tables, you have to do this task multiple times.
- Sometimes there is no way to know when a data table is going to be available. Because of this, enabling the rules manually (previous drawback) can be difficult to manage.
- If you work with clients there is a chance you lose access to the Sentinel environment before the data tables are introduced.
Story time: During one of my older engagements, I encountered the same issue. Rules needed to be deployed but the data table was not ready yet. I had to wait for the client to configure their systems to forward the data into multiple custom data tables. They provided me access to their environment but only for a limited time. At that time, I was not aware of a better solution, so I created them a script that tried to enable the rules every day. The idea behind the script was if the data table is available then enabling the rules should be successful. Some issues with this solution: 1. We generated cost to the client due to the continuous script execution. 2. The script was executed once a day, so enabling the rules was not instantaneous. 3. We had to ensure the script turns off once all the rules are enabled.
3. Push fake logs into the data table in Sentinel
This is one of the solutions I can recommend but it has its limitations. You can push logs to a specific data table in Sentinel, and when you forward the first log Sentinel creates the data table for you. There are multiple ways to forward a log to Sentinel and thus create a data table. One of the options is to use PowerShell and send logs to Sentinel with a script. You can also deploy a LogStash server and forward the test events to a custom table in Sentinel by using that server.
This way the rules can be deployed before the real log forwarding starts. Normally, we have to wait for the real logs, so Sentinel creates the data table for us. We practically enforce the same data table creation by sending our fake logs to Sentinel.
The custom data table (_CL) creation is solved with this solution. Also, because we can push any logs into these custom tables, we can even test our rules.
But there are also default tables in Sentinel to which we cannot manually forward logs. The schemas of default tables are in Sentinel even when there are no logs. We can deploy rules every time with these tables in them, but we cannot test the rules because of the inability to push fake/test logs into these tables.
You can push logs into some of the default tables like CommonSecurityLogs or Syslog table.
Benefits:
- The rules can be deployed and enabled before the real logs show up to create the table.
- You can automate it from a single system (see below).
Drawbacks:
- The method needs some infrastructure outside of Sentinel. Either a PowerShell script executed from Cloud Shell or Azure Functions, or an external server to forward data to specific tables. You can use this to your benefit though if you are an MSSP with a lot of clients. You can set up one LogStash server and you can automatically push data into all your new clients’ environment, thus creating the tables.
- Pushes data to Sentinel which will introduce ingestion and retention cost. Typically non-significant amount though.
4. By using Azure functions
This is my preferred method of deploying rules without the necessary data and tables in Sentinel. Microsoft’s SIEM lets you create Functions which you can call from any query or rule. Also, the naming of these Functions is not limited at all, so you can create a function with the name of the table you would like it to represent.
Let’s say you expect your EDR to forward logs into the MagicEDR_CL table. You want to deploy the rules, but the EDR is not configured yet, so the table also does not exist at this point. You can put together a query in Sentinel and save it as a function under the name “MagicEDR_CL”. A rule that uses the MagicEDR_CL table will call the function with the same name if the table does not exist.
After the function is ready, you still have to define some value in it. The rule can only be deployed successfully if the fields it uses do exist.
I want to create a rule that triggers if the MagicEDR_CL table contains three ‘malicious’ events on the same machine. You can create a function like this that is not only going to let you deploy the rule but also going to trigger it to be able to test the whole automation chain.
|
|

This is obviously an oversimplified solution, but you get the gist. You can store more complex logs the same way. Also, you can use externaldata operator to store the logs in an external file, or the datatable operator to store it in a more elegant way.
Collecting the necessary fields for all your existing rules can be painful and tedious. However, it is a good practice to store the logs that triggered a rule during its initial test after creation in a repository. This data can be useful to test the rule after changes, or to test the rule with the whole automation chain during its deployment in a new environment. And if you already have this data, you only need to add it to a function and then define the necessary fields.
But what happens when the real logs are starting to flow into Sentinel and a new Data Table is created with the same name as your function? Well, this is the best part. If Sentinel has a function and a data table with the same name, it is going to ignore the function. So, with this method, you are able to deploy the rules, and what’s more, you are also able to test the rules and then you can just ignore it. Once the real data creates the table, the rule in Sentinel will immediately monitor that data and not the fake information in the Function. The only thing you are going to see during a query execution is a notification:

Benefits:
- The rules can be deployed and enabled before the real logs show up to create the table.
- Everything can be done in Sentinel; no external resource is needed.
- Easy to deploy in an Infrastructure-as-a-Code way directly in Sentinel.
Drawbacks:
- You must ensure the logs are as close to the real ones as possible. It can be an issue because everything is defined by you without pushing anything through the ingestion pipeline. Less of a problem with the previous method but in some situation it can still be an issue.
- You are going to have unnecessary functions in Sentinel. Not a big problem, but messy.
When I’m talking about testing the rules in this post you must know that I am not talking about testing the implementation quality of the rule. If you implemented the rule incorrectly but you were the one who defined the logs to trigger the rule, then a test like this will not reveal the issue. Rule test in this blogpost merely means to check whether the rule is triggered by the same event it did in other environments. To see whether the rule is deployed, deployed correctly, enabled and whether it can trigger the necessary automation logics.
So, we can deploy any rule if it is based on a default table because those tables are always there in Sentinel. We can also deploy any rule that uses custom tables by using method 3 or 4. We can test our rule by pushing data into custom tables, but we cannot test our rule if it is based on a default table because we cannot push logs into default tables (with some exceptions like Syslog or CommonSecurityLogs).
From this point on, it should not be an issue for you to deploy a rule even if the used tables do not exist in Sentinel.