When you deal with logs and events in an environment you have to ensure that your log sources and forwarders are up and running. Monitoring the health of these devices is crucial. You can have the best SOC team in the world and a ‘catch all attack’ detection rule collection, but without logs they are useless. Having a log source down for months can also be problematic from a compliance point of view.

You can take multiple approaches to create analytic rules to detect a disruption in log ingestion/generation. All methods have their drawbacks and advantages. In this –short- post I’m going to explain how I handle health rules in a generalized way and still allow my clients to be able to easily fine-tune these detections.
Ways to go
You can handle health rules in various ways and all of them have their pros and cons. In this blog post, I am only going to go into details about the method I use most of the time and make a high-level introduction to the other solutions.
1. Individual health rules for each log source
One of the most trivial solutions is to create an individual rule for each log source (datatable) you want to monitor. With a rule like this, you only have to query the datatable and create an alert when the query does not return any results. This means the given log source has not generated any logs during the queried time-window, so the source is possibly down.
This solution – just like any other – has some drawbacks. It can be difficult to manage because you have to create one rule for each log source. Any modifications that affect all sources must be carried out in all of the rules one-by-one.
2. Anomaly-based detection
You can create an anomaly-based rule to detect changes in log ingestion. You can make one per log source or just a global one to cover all your tables. With this method, you can detect issues with log sources that you couldn’t do with other types of rules. Like when the log forwarder is overloaded, and it can process only a lower number of events.
But due to its behavior, this method also has some problems. Sometimes a lower number of logs are part of the normal operation, still, this can incorrectly trigger the rule creating an FP alert. Like the lack of logs during Christmas, when a lot of people are on vacation is not odd at all.
It can also miss the detection of a log source downtime when multiple systems send the traffic through the same forwarder. You can have 10 systems, all sending logs to Sentinel through the same forwarder. If you only monitor the forwarder, it can be difficult to detect when one of the end systems is down, simply because a 1/10 decrease in incoming logs can be lower than the trigger threshold.
There are some other potential problems with this method. Thus, I think it is not a good method in itself to detect silent log sources. On the other hand, it can be a good addition to other types of detections.
3. Using the ‘Usage’ table
If you want to create only one rule to cover all the log sources, somehow you have to collect data from all tables into one query. The ‘Usage’ table in Sentinel is a table that contains information on the ingested data for all the other tables. The ‘Usage’ table is updated hourly, and it contains one entry per log source (datatable) if the source created any event in the last 1 hour.
So, a rule can be simple. Define the tables you want to monitor in a list. If any tables from the list do not appear in the Usage table, then it has no events from the last 1 hour, thus our rule can create a silent log source alert. Or, if you don’t want to pre-define the tables you can just check whether there was an entry for a datatable in the Usage table 2 hours ago, but not in the last hour. If this is the case, it means a log source potentially has been down for an hour.
The drawback of this solution is that the ‘Usage’ table only contains info at table-level. Let’s say you have 4 Windows machines and all of them send messages into the SecurityEvent table. If one system is down, there will still be some events in the SecurityEvent table. In a situation like this, you actually want to detect downtime at the Computer-level and not at table-level (SecurityEvent). This is something you can’t do with the ‘Usage’ table. Otherwise, this option is a good one, because it is lightweight and simple.
Usage
| summarize arg_max(TimeGenerated, *) by DataType
| where TimeGenerated < ago(2h) This rule lists all DataTables which contained events in the last 24 hours (default time filter) but nothing from the last 2 hours. So, an alert like this indicates that a log source has been down for at least 2 hours.
4. Using ‘union’ and watchlists
There is no problem with the previous methods. All of them can be used in specific scenarios. However, this version is the one I use the most. The reason behind this is that a lot of my clients want to be able to define which table to monitor and based on which field of the event. It is also a common request to be able to define for how long a system/source should be down before an alert is created. So, this method of mine is there to provide a centralized way to handle these configurations.
I am going to explain my solution through an example. Let’s say you have the following log sources and requirements:
- magic_edr: You want to monitor when a machine does not send events to Sentinel for 4 hours. For this, you want to use the table ‘magic_edr’ and the field ‘Computer’.
- OfficeActivity: Create an alert when any of the OfficeWorkload in the OfficeActivity table did not create an event for 1 hour.
- CommonSecurityLog: Monitor when a server is down for more than 1 hour. For this, use the CommonSecurityLog table and the ‘Computer’ field, because you are not only interested when the Syslog forwarder is down, you want to detect when a given machine (log source) is down.
First – as a test – create an inline datatable with the values my test code is going to need. You will always need a ‘DataTabe’ field to define which source you want to monitor. The TimeWindow defines the timespan after which the rule is going to trigger if there are no logs in the given table. After these two mandatory fields define all the other fields you want to use for correlation for any of the log sources. In my example, these are the ‘OfficeWorkload’ and ‘Computer’ fields.
Then add the entries to the inline datatable. The first field is going to be the name of the table. The second one is the previously explained TimeWindow. And then add the word ‘use’ if you want to use the given field for this table for correlation and anything else if you don’t want to use that field.
let tsts = datatable (DataTable: string, TimeWindowT: timespan,ComputerT: string, OfficeWorkloadT: string)
["CommonSecurityLog", "0.01:00:00", "use", "not",
"OfficeActivity", "0.01:00:00", "not", "use",
"magic_edr", "0.06:00:00", "use", "not"]; To represent 1 hour I used the “0.01:00:00” format instead of the “1h” format. I had issues with the latter one here and there during type casting, so I decided to go this way whenever possible.
Once this is done, you have to query all of your logs from various tables (union), and you have to correlate the created datatable with these logs with a join. The name of my datatable is ’tsts’.
union withsource=DataTable *
| join kind=inner (tsts) on $left.DataTable==$right.DataTable
| where TimeGenerated < ago(totimespan(TimeWindowT)) With this part of the query, you added some new fields to each entry. So now, each entry contains the information of which of its fields should be used for downtime detection and after how much time an alert should be created.
I used inner join because I only want to monitor logs that are in the datatable, and I am only interested in tables in which we have recent logs. So once a log source goes down, I want to detect it, but I don’t want to create alerts over and over again.
The arg_max command is going to help to find the newest entry per defined field.
| summarize arg_max(TimeGenerated,*) by DataTable, Computer, OfficeWorkload To make it work, all the fields that will be used have to be defined after the ‘by’ word. But if a table exists in an event and we don’t want to use it for correlation then this configuration won’t work properly. The above command is going to create one output for each DataTable, Computer, OfficeWorkload pair. If my magic_edr log source contains an OfficeWorkload field, then it will create an output for each different value in that field. But I don’t want to use this field for magic_edr. To eliminate this problem, you must simply overwrite the OfficeWorkload value to a common dummy string. This way all the entries are going to contain the same value, therefore only 1 output is going to be created per Computer. This way, you won’t differentiate between various OfficeWorkloads for the magic_edr log source. So, this is the way to go if you don’t want to use a field for a given table.
At the same time, you won’t modify this field in the OfficeActivity table, so there, you can still use the OfficeWorkload field to differentiate between workloads.
| extend Computer = iif(ComputerT == "use", Computer, ComputerT)
| extend OfficeWorkload = iif(OfficeWorkloadT == "use", OfficeWorkload, OfficeWorkloadT)
| summarize arg_max(TimeGenerated,*) by DataTable, Computer, OfficeWorkload
| where TimeGenerated < ago(totimespan(TimeWindowT)) This part of the code checks whether a field is set to be used - “use” - or not - anything else. If it is set to be used, you will keep the value intact. Otherwise, overwrite it with a dummy value (in my case with “not”). After this, the code simply picks the newest event from all groups (DataTable – Computer – OfficeWorkload) and then creates an output of the freshest event that is older than the defined timespan (TimeWindow).
I added a ‘T’ after all of the fields in the inline datatable to ensure no field with the same name exists in any of the tables I use. Otherwise, in case of matching fieldnames, a ‘1’ character is appended to the name of one of the fields. Thus, the name of the fields won’t be predictable.
So, the full test code:
let tsts = datatable (DataTable: string, TimeWindowT: timespan,ComputerT: string, OfficeWorkloadT: string)
["CommonSecurityLog", "0.01:00:00", "use", "not",
"OfficeActivity", "0.01:00:00", "not", "use",
"magic_edr", "0.06:00:00", "use", "not"];
union withsource=DataTable *
| join kind=inner (tsts) on $left.DataTable==$right.DataTable
| extend Computer = iif(ComputerT == "use", Computer, ComputerT)
| extend OfficeWorkload = iif(OfficeWorkloadT == "use", OfficeWorkload, OfficeWorkloadT)
| summarize arg_max(TimeGenerated,*) by DataTable, Computer, OfficeWorkload
| where TimeGenerated < ago(totimespan(TimeWindowT))Based on my experience, a lot of people and companies do not like to use Watchlists. When Microsoft came out with the Watchlist functionality it was pretty limited. But since then, MS worked a lot on this option, and I think at this point it is a convenient tool in Sentinel. The reason I chose this tool is that it is easy to use by clients who are not too familiar with this SIEM yet.
Options to store the fields and the time value instead of in a Watchlist:
- You could use datatable-s as I did in my example, but it means storing data in the rule itself. This is not a good practice in general. For an MSSP, this choice makes rule management and enhancement difficult. It is good for testing though.
- You could store the information in an external file, but it requires additional access outside of Sentinel. This is something I try to avoid most of the time.
- It is an option to store the value in a Sentinel function. This can work well for an MSSP, but for the client itself, it is not the easiest way. Even though it is only a few steps, navigating to a function is not straightforward if you are not familiar with Sentinel. Also, due to a bug, sometimes it is not possible to save a function, which is bad from a client satisfaction point of view.
Due to these limitations, I like to go with watchlists. These are just CSV tables, which are easy to modify, you can create a backup of them, and they are easy to process.
So, putting the previous code snippets together and replacing the inline datatable with a Watchlist:
union withsource = DataTable *
| where TimeGenerated > ago(60d)
| join kind=inner (_GetWatchlist('HealthMonitor')) on $left.DataTable==$right.DataTable
| extend Computer = iif(ComputerT == "use", Computer, ComputerT)
| extend OfficeWorkload = iif(OfficeWorkloadT == "use", OfficeWorkload, OfficeWorkloadT)
| summarize arg_max(TimeGenerated,*) by DataTable, Computer, OfficeWorkload
| where TimeGenerated < ago(totimespan(TimeWindowT)) And this is how my ‘HealthMonitor’ Watchlist looks like:
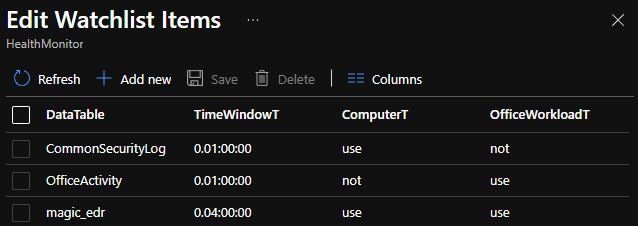
So, in the end, I just replaced the datatable with a watchlist, but you can still use the datatable for testing.
Unfortunately, I could not find a way in Kusto to dynamically address and modify columns. KQL is really versatile, and I still learn something new every week. Thus, there is a chance a functionality like this exists somewhere, but for now, you have to add all of the fields you are going to use manually one-by-one like this:
| extend Computer = iif(ComputerT == "use", Computer, ComputerT) When you don’t need a field at all, do not add it to the query. Your query will return an error if the schema of the tables you union together does not contain the given field.
This method still involves a hefty amount of manual work. Until I can find a dynamic way to handle columns, you can just create a code to put together the initial query and the watchlist for you based on your clients’ needs.
Summary
This query is a prototype to detect when one of your sources is down. By using Watchlists you can easily modify what you want to monitor and how. Also, you can offer a straightforward solution to your clients to do the same without your involvement. I suggest you try to use Watchlists more often as it is a nice but still underutilized tool.