I’m pretty sure you’ve already dealt with the ingestion delay issue if you use a SIEM with scheduled rules. There are numerous articles on the internet that explain how to handle ingestion latency without missing any events and without having your rules double-process a log. While these blog posts are excellent, they frequently do not explain the issues with ingestion delay variance. Here, I’ll walk you through a specific use-case of how to detect X number of events in Y time while accounting for ingestion time fluctuations without missing any detections.

If you are new to the ingestion delay problem with scheduled rules, take a look at Microsoft’s article about the topic. In addition, I published my solution to the ingestion delay issue in dynamic environments.
It is important to point out that using these general solutions to eliminate the delay problem will not work that well if you want to create a detection for multiple events in an environment with high ingestion delay variance. In our situation sometimes you want to process an event multiple times. If two events were generated close to each other but arrived to Sentinel with different delays, you want to ensure they are processed by the same rule iteration at least once regardless of their ingestion time.
Use case
To explain the options, I’ll use basic brute-force detection logic.
A brute-force attempt is defined as 5 failed logins in 5 minutes for the same user.
In my rule, I’m using the following datatable to make it easier to replicate my tests and explain the issues.
let Logins = datatable (TimeGenerated: datetime, User: string)[
datetime(2022-10-11 10:00:00), "John",
datetime(2022-10-11 10:01:30), "John",
datetime(2022-10-11 10:02:02), "John",
datetime(2022-10-11 10:03:03), "John",
datetime(2022-10-11 10:05:11), "John",
datetime(2022-10-11 10:05:12), "John",
datetime(2022-10-11 10:05:13), "John",
datetime(2022-10-11 10:07:01), "John",
datetime(2022-10-12 10:07:01), "John",
datetime(2022-10-12 10:07:02), "John",
datetime(2022-10-12 10:07:03), "John",
datetime(2022-10-12 10:07:04), "John",
datetime(2022-10-12 10:07:05), "John",
datetime(2022-10-11 10:00:01), "Pete",
datetime(2022-10-11 10:00:02), "Pete",
datetime(2022-10-11 10:00:15), "Pete",
datetime(2022-10-11 10:01:01), "Pete",
datetime(2022-10-11 10:06:01), "Pete",
datetime(2022-10-11 10:06:02), "Pete",
datetime(2022-10-11 10:06:03), "Pete",
datetime(2022-10-11 10:06:04), "Pete",
datetime(2022-10-11 10:07:01), "Pete",
datetime(2022-10-11 10:19:01), "Pete",
datetime(2022-10-11 10:19:02), "Pete",
datetime(2022-10-11 10:19:03), "Pete",
datetime(2022-10-11 10:20:05), "Pete",
datetime(2022-10-11 10:20:06), "Pete",
]; The large blue boxes in the figure below indicate which occurrences I would like to see in a single detection. Therefore, I would like to see 4 detections (incidents) based on these events. Which activities would be included in each 5-minute group are shown by the colorful lines. One can see that for John we have 2 mostly overlapping groups. There are more than five minutes between the first event in red and the last one in green. They are in a different 5-minute group as a result. However, given that they overlap, I would prefer to regard them as a single incident.
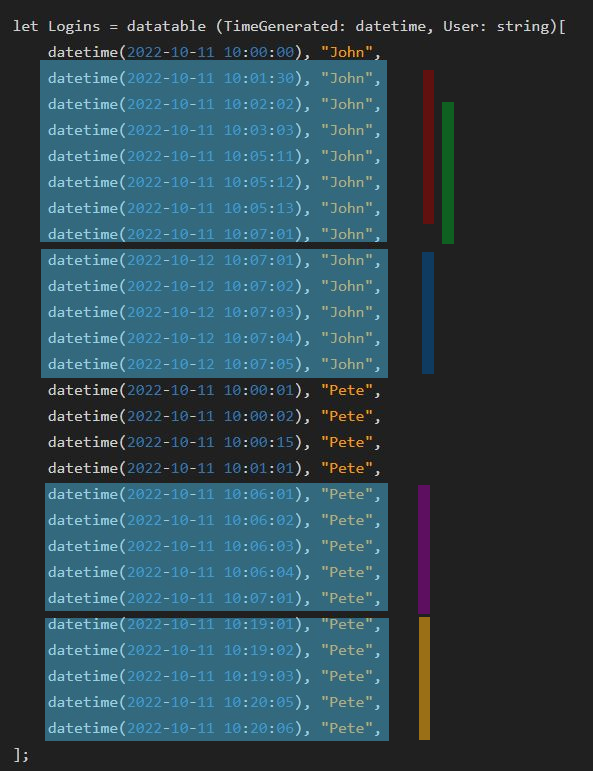
In an ideal environment
Events don’t have a propagation time in a perfect world. They also don’t have ingestion delays, or at the very least, the delay is the same for all log types. In other words, if event A and event B were created with a 2-minute gap, they would also be present in your SIEM with a 2-minute gap.
In an ideal world, one of the simplest solutions would be to establish an Analytics rule with a lookback time of five minutes that checks to see if a user experienced more than five failed logon attempts. This rule must be run every 5 minutes.
This is the Analytics rule settings:

And this is how the KQL query itself would look like:
Logins
| summarize count() by User
| where count_ >= 5 No time filtering is required because the rule only checks the last 5 minutes, so this filter is indirectly in the rule already.
But, Sentinel’s world is not perfect. Logs have ingestion delay and variance, which causes us some issues:
- Assume five logs were created 10 seconds apart. So the first is at 00 seconds, and the last is at 40 seconds. The last log takes 20 minutes longer to reach Sentinel than the other logs, which all arrive with a 1-minute delay. Because the last event is not yet in Sentinel, the first rule execution at 5 minutes checking the logs from the previous 5 minutes will not see it.
To solve this, you must extend your rule beyond the last 5 minutes. You must go back far enough to cover logs with longer ingestion delays. You have to modify the query to ensure that it only counts failed logins that occurred within 5 minutes of each other.
Sentinel’s rule engine has a default delay of 5 minutes. I’m ignoring this in this post for the sake of clarity.
Bucket-based solution
Typically, people use buckets or bins to try to alleviate this inconvenience. You can group events based on rounding by using buckets. In this case, you could round all TimeGenerated fields to a minute divisible by 5 and group all events into 5-minute buckets. So, events with a TimeGenerated field between 00 minute 00 second and 04:59 would be placed in bin 0, while events with a TimeGenerated field between 5:00 and 9:59 would fall in bin 1.
As a result, the rule query becomes as follows:
Logins
| summarize count() by bin(TimeGenerated,5min), User
| where count_ >= 5 So, if a bucket contains at least 5 failed logins, it means that at least 5 unsuccessful logins occurred in 5 minutes. This only captures events that are maximum 5 minutes from each other, so, you can now change the rule to look back more than 5 minutes. Unfortunately, this is not a complete solution because it will miss some brute-force attempts.
If there are four login failures at 4:59 and four events at 5:00, four logs will be placed in the first bucket and four in the second one. Even though 8 failures occurred in 1 second, our rule will not detect them because they will end up in different bins.
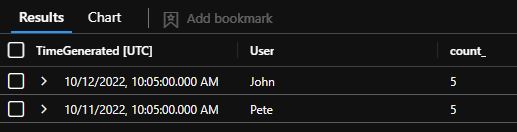
If we create a rule like this and run it on our dataset, we see that a few detections are missed. Even though there are four activities in which at least five failures occurred in five minutes (explained in the first image in the post), two of these activities have some events in bucket A and others in bucket B, causing the bin-based detection to miss them:
To ease the pain, use multiple 5-minute buckets rather than one with some overlaps. One can create 5 buckets with a 1-minute delay in them. The bin_at command can be used to achieve this.
bin_at(TimeGenerated,5min,todatetime('2022-10-11 10:06:00'))
# This is one minute delay compared to 10:05:00, which would be a 0-minute delay in a 5min bucket.This solution makes use of five buckets rather than just one. The advantage is that you can reduce the possibility of a False Negative (real Brute-Force goes undetected). The disadvantage is that you will not completely solve the problem, but your query will be uglier and heavier.
In the original problem, you can miss brute-forces where the events are maximum 5 minutes apart (based on our use case) but minimum 1 second apart. Using 5 5-minute buckets with a 1-minute delay, you can only miss events that are no more than 5 and no less than 4 minutes apart. So, you eliminated 80% of the False Negatives. However, there is still a chance of some brute-force attempts to stay under the radar.
In the fancy excel-based image below, I explain which of John’s failed logins would fall into which bin in a Multi-bucket scenario. The same color under two distinct events indicates that they fell into the same bucket.
It is clear that events in columns C, D, E, and G with a 1-minute delay bucket would result in a detection. We have 6 events for John in these 4 columns, and 5 is already a brute-force attempt. We’d also make a detection for the bucket with a 2-minute delay and another for the bucket with a 3-minute delay. Columns D,E,G (5 events) and E,G,I (5 events) would be detected in these cases. So, three distinct bins would trigger our detection; we simply need to ensure that they all result in one detection in the end (for example, with a make set command).
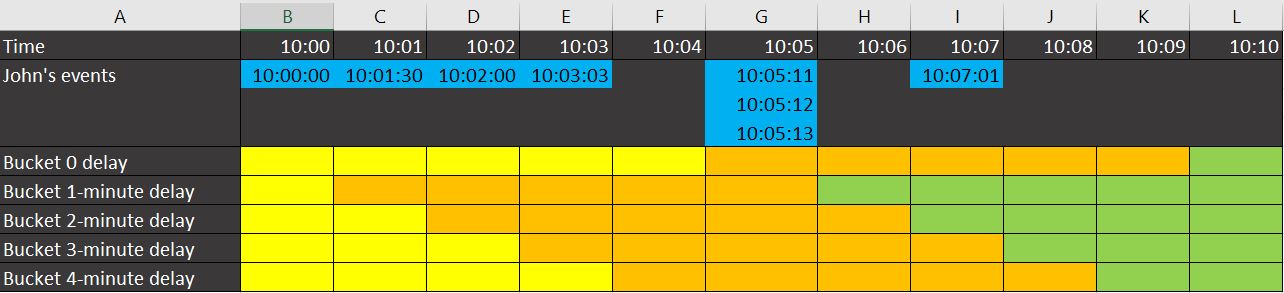
Legend:
- Blue: actual events created by John’s failures
- Yellow / Orange / Green: separate buckets
While not a perfect solution, bins (or multi-bins) can be a good fit for some scenarios. If you have prior information on your dataset you can define a bin that fits your data corpus. Sometimes the bins are already fixed by your use case. Let’s say you want to count the occurred events per day. In this case, one bin is going to be one day from day start to day end. However, as you can see in our example, it is not always a reliable solution.
Reconsider the problem
Before moving forward…
Why did you select the number you used in the rule? A brute-force attack should be considered 100 failed logins. How about 99? And 98? Is 50 (half of the original number) something you’re okay with the rule detecting?
The numbers in these rules are sometimes completely arbitrary. If half of your original number is still something you want to detect, the single-bin solution will work perfectly for you. The worst-case scenario for you is 50 events in the first bin and 50 events in the second bin. With the number 100 in the rule, this would be missed, but if you are fine with detecting only 50 failed logins, you can decrease the number to 50.
And why did you select 5 minutes as the detection time? It is fine, but if 100 failed logins in 5 minutes is interesting, how about 6 minutes? Is a slower attacker something you want to avoid detecting? How about 100 failed login attempts in 10 minutes?
You can make your job easier if you can relax your problem. If you only use your queries for enrichment or as part of a correlation rule (rather than handling them individually), your event numbers and time window may not need to be as strict. In this case, using the previous solutions may be sufficient.
THE Solution
In the last section, I am going to show a solution to detect the exact brute-force activity and two separate ways to enrich the findings with more information.
We want to cover the same use case: 5 failed logins by the same user in 5 minutes. Let us rephrase it slightly to make this solution more simple. Assume the logs are sorted by User and then by the TimeGenerated field. The question then becomes:
- Does the 4th event (this event + 1,2,3,4 = 5) from the current one include the same User? If it is for a different user, it means not enough failed login happened for the current user starting from this event.
- If the user is the same, is the time difference between the current event and the fourth one less than 5 minutes? If this is the case, the user has had at least 5 failed logins in the last 5 minutes.
So, in case of a ‘Yes’ answer to these questions we have a detection on our hand. And putting together a query for this activity is straightforward.
With the ’next’ command we can check what is the content of the User and TimeGenerated fields in different event. In our case in the 4th event from the recent one.
Logins
| sort by User, TimeGenerated asc
| extend 5th_event_User = next(User,4)
| extend 5th_event_TimeGenerated = next(TimeGenerated,4)
| where User == 5th_event_User
| where TimeGenerated + 5min >= 5th_event_TimeGenerated We now have all of the events that constitute the start of a Brute-Force activity. However, after this filtering if there are only five events, we will only see the first one and not the other four. (Technically, the last 4 events will be filtered out every time). As a result, some enrichment is required to ensure that all of the relevant events appear in the final result.
1. Enrich with join
The first enrichment option is to use join to find all the relevant events. This solution has the advantage of being quite simple. The disadvantage is that it can be very heavy if you are in an environment with a high number of failed logins and brute-force attempts to detect.
So, we can just extend our previous query with a join. We connect our prefiltered events to the Login table. I use an ‘inner’ join to match all data from the first set to all data from the second set based on the matching User values. TimeGenerated (without the ‘1’ at the end) represents the time when a brute-force could have begun (see the previous section of the query), and TimeGenerated+5min is the time when the given ‘bin’ ends. An event is a part of a brute-force attack if its own TimeGenerated field (TimeGenerated1 field) is between these values.
| join kind=inner Logins on User
| where TimeGenerated1 >= TimeGenerated and TimeGenerated1 <= TimeGenerated+5min
| summarize make_set(TimeGenerated1) by User One event can be part of multiple brute-force buckets, so I just eliminate the duplications with the make_set operator. Depending on the field and information required, you can deal with duplications in a variety of ways.
2. Enrich with scan
The ‘scan’ operator is far more difficult to use than a simple ‘join.’ While it is more complex, the ‘scan’ command has the advantage of providing many additional features. These additional capabilities may not be required in my example, but they may be useful in other situations.
If you are interested in scan, you can read about it here.
The code:
Logins
| sort by User, TimeGenerated asc
| extend goodMatch = User == next(User,4) and TimeGenerated + 5min >= next(TimeGenerated,4)
| scan with_match_id=session_id declare (sessionLast:datetime, sessionUser:string="") with
(
step s1 output=all:
goodMatch == "true" =>
sessionLast = TimeGenerated,
sessionUser = User;
step s2 output=all:
goodMatch == "false" and s1.sessionLast + 5min >= TimeGenerated and User == s1.sessionUser;
step s3 output=none:
s1.sessionLast + 5min < TimeGenerated or User <> s1.sessionUser ;
) As can be seen, we don’t do any filtering at the start here; we simply mark some events as a ‘goodMatch’. A ‘goodMatch’ indicates that it can be the first event in a potential brute-force attempt, meaning the 4th event from this one is for the same User and it is less than 5 minutes away from the current one.
The next() and scan operators require serialized data. This can slow down the processing and make the query heavier (Memory-wise). So, be careful.
A ‘scan’ command is made up of multiple steps, each of which can refer to the state of a previous step.
- s1: If an event is marked as ‘goodMatch,’ we proceed with the first step. This means that this is an event that can be or is a start. The sessionLast field will contain the most recent TimeGenerated value when the event is a ‘goodMatch.’ The upper limit of +5mins will begin here. So, if there are eight events in a row, the fourth event’s TimeGenerated field will be the sessionLast, and the eighth event must be maximum 5 minutes later. So, with this, we ensure we include the 4 events which would be missed without enrichment.
- s2: We also want to see events that aren’t a ‘goodMatch’ but are within 5 minutes of one. For the last 4 events, the 4th event from each one of them is either for a different User or it is farther away than 5 minutes. If this was not the case they would be marked as’goodMatch’. The S2 step is here to assist us in identifying these events since they are part of a brute-force pattern.
- s3: We ignore the remaining events for this session if we are more than 5 minutes away from the sessionLast value or have reached a new user in our logs. We filter out these events with output=none. After that, a new session can be launched.
The end
Before you create a query to detect anything based on the number of occurrences in a brief period, consider how stringent your requirements are. Are you willing to compromise on the numbers or the time frame? If this is the case, you may be able to create a simple query with no complications.
Check to see if using bins (or multiple bins) is a viable option for you. For example, buckets can be the simplest and fastest option for anomaly detection, for a query with fixed starting and ending times (day start/day end), or graph rendering.
And if you cannot chill at all, you should consider our Final solution with its capabilities and limitations.