
When it comes to managing logs in Microsoft Sentinel, shared tables like Syslog, CommonSecurityLog, and AzureDiagnostics often serve as the default destinations for consolidating data from various solutions. While forwarding logs to these tables aligns with Microsoft’s ‘best practices’, this approach comes with significant limitations that have only grown as Microsoft introduced new features. In this post, we’ll explore the drawbacks associated with utilizing these tables and discuss why avoiding them can be advantageous.

In Microsoft Sentinel, most data sources have their own dedicated tables, but some solutions share the same tables. In these shared tables, logs from multiple solutions are stored together. For instance, the CommonSecurityLog table can contain logs from Cisco ASA, Fortinet, and Palo Alto firewalls. While consolidating different logs in one place may seem convenient, it comes with its own set of drawbacks.
The widespread use of these shared tables has led many solutions (like parsers and rules) to become heavily dependent on them, making the transition to more efficient alternatives challenging. However, the advantages gained from switching to dedicated tables often outweigh the drawbacks, making the effort worthwhile in the long run.
Next, we dive into these shared tables, examine the type of data they store, and explore the issues they present.
Shared Tables
The tables below are the typical ones commonly used as shared tables.
1. Syslog
The Syslog table in Microsoft Sentinel serves as a central repository for logs originating from Linux machines, either directly or indirectly. It primarily contains two types of data:
- Linux machine logs collected via the AMA agent
- raw Syslog-formatted third party logs gathered through a Syslog collector (still via AMA)
 Cisco FTD logs in the shared Syslog table - all the data is stored in the SyslogMessage field
Cisco FTD logs in the shared Syslog table - all the data is stored in the SyslogMessage field
2. CommonSecurityLog
This table is designed to store data from third-party devices, primarily network devices, that support CEF-formatted logs. While the data still travels via Syslog, the custom CEF format allows for more efficient parsing and pre-parsing (by the agent) compared to raw Syslog logs.
 Palo Alto log in the shared CommonSecurityLog table - all the unparsed data is stored in the AdditionalExtensions field
Palo Alto log in the shared CommonSecurityLog table - all the unparsed data is stored in the AdditionalExtensions field
3. AzureDiagnostics
The AzureDiagnostics table is used to store logs from the majority of Azure PaaS resources. However, even Microsoft has acknowledged that this approach is not the most efficient, which is why some PaaS resources now have their own dedicated tables. Despite improvements, the AzureDiagnostics table remains widely used due to existing content built around it and the lack of dedicated table support in some PaaS solutions.
 Azure Firewall log in the shared AzureDiagnostics table - all the unparsed data is stored in the msg_s field
Azure Firewall log in the shared AzureDiagnostics table - all the unparsed data is stored in the msg_s field
Challenges
Storing logs from multiple sources in shared tables may seem efficient at first, but it introduces several challenges that can affect performance, cost, and functionality. Key issues:
- Query Performance: Shared tables grow large by consolidating data from multiple sources, slowing down queries that need to scan the entire table. Early filtering can help, but when it’s not feasible (e.g. with messy Syslog logs), query performance suffers.
- Parsing Complexity: Logs from different sources often have inconsistent or non-standard formats within shared tables, complicating pre-parsing and making it harder to extract information efficiently. Pre-parsing done by the AMA agent, especially on raw Linux logs, tends to be incorrect and can result in log loss or information loss.
- Increased Cost: Shared tables often use a “collector” field for unparsed or miscellaneous data, which can be hard to interpret and significantly increases log size. Properly parsed logs are much smaller. The lack of parsing inflates the ingestion costs in Sentinel. The “collector” fields are the ‘SyslogMessage’ field in the Syslog, ‘AdditionalExtensions’ field in CommonSecurityLog and the ‘msg_s’ field in the AzureDiagnostics table.
- RBAC Limitations: Table-level Role-based access control (RBAC) will be limited. With shared tables, users either gain access to all log sources or none in a table, limiting granular access control and potentially increasing security risks.
- Retention Constraints: Retention policies are table-wide. If log sources require different retention periods, a shared table forces a uniform policy, complicating compliance and increasing costs.
- Archived Data Costs: Accessing archived data through restore or search jobs is costly with shared tables, as both functions process the entire table.
- Usage Analysis Challenges: The Usage table provides metrics at the table level. Shared tables reduce granularity, making it harder to analyze individual log source usage.
- Auxiliary Log Tier Restrictions: The Auxiliary log tier offers lower-cost storage but applies at the table level. Shared tables prevent selective tiering of logs, limiting cost optimization for non-critical data.
| Challenge | Syslog | CommonSecurityLog | AzureDiagnostics |
|---|---|---|---|
| 1. Query Performance | 2 | 2 | 2 |
| 2. Parsing Complexity | 3* | 2 | 2 |
| 3. Increased Cost | 3** | 3** | 2 |
| 4. RBAC Limitations | 2 | 2 | 2 |
| 5. Retention Constraints | 2 | 2 | 2 |
| 6. Archived Data Costs | 2 | 2 | 2 |
| 7. Usage Analysis Challenges | 2 | 2 | 2 |
| 8. Auxiliary Log Tier Restrictions | 2 | 2 | NA |
* Syslog logs are frequently misinterpreted during pre-parsing by the AMA agent. This leads to challenges in identifying log sources and additional parsing. In many cases, parsing must ineffectively occur prior to filtering. This also affects query performance.
** All options increase costs, but Syslog lacks parsing, and CEF data often has longer field names. The exact costs vary based on the log source.
Using dedicated tables for each log source can address these challenges by improving performance, reducing costs, and enabling greater flexibility in management and compliance.
While shared tables have both drawbacks and benefits, using dedicated tables often provides greater advantages. However, before making the switch, it’s important to carefully evaluate the potential impact.
The new way
While log source type based separation is effective, Microsoft’s strategy for Azure PaaS resources takes this idea even further by creating a more granular setup.
Microsoft has gradually introduced support for dedicated tables not only for each resource type but also for log types within each resource type. For example, with Azure Firewall, you can choose between sending logs to the shared AzureDiagnostics table or to dedicated tables for specific Azure Firewall log types. These include:
- AZFWApplicationRule: Logs for application rule matches
- AZFWFlowTrace: Logs for flow tracing
- AZFWFatFlow: Logs for aggregated flow data
- AZFWNatRule: Logs for NAT rule matches
- AZFWDnsQuery: Logs for DNS queries
- AZFWIdpsSignature: Logs for intrusion detection/prevention signatures
- AZFWInternalFqdnResolutionFailure: Logs for internal FQDN resolution failures
- AZFWNetworkRule: Logs for network rule matches
- AZFWThreatIntel: Logs for threat intelligence detections
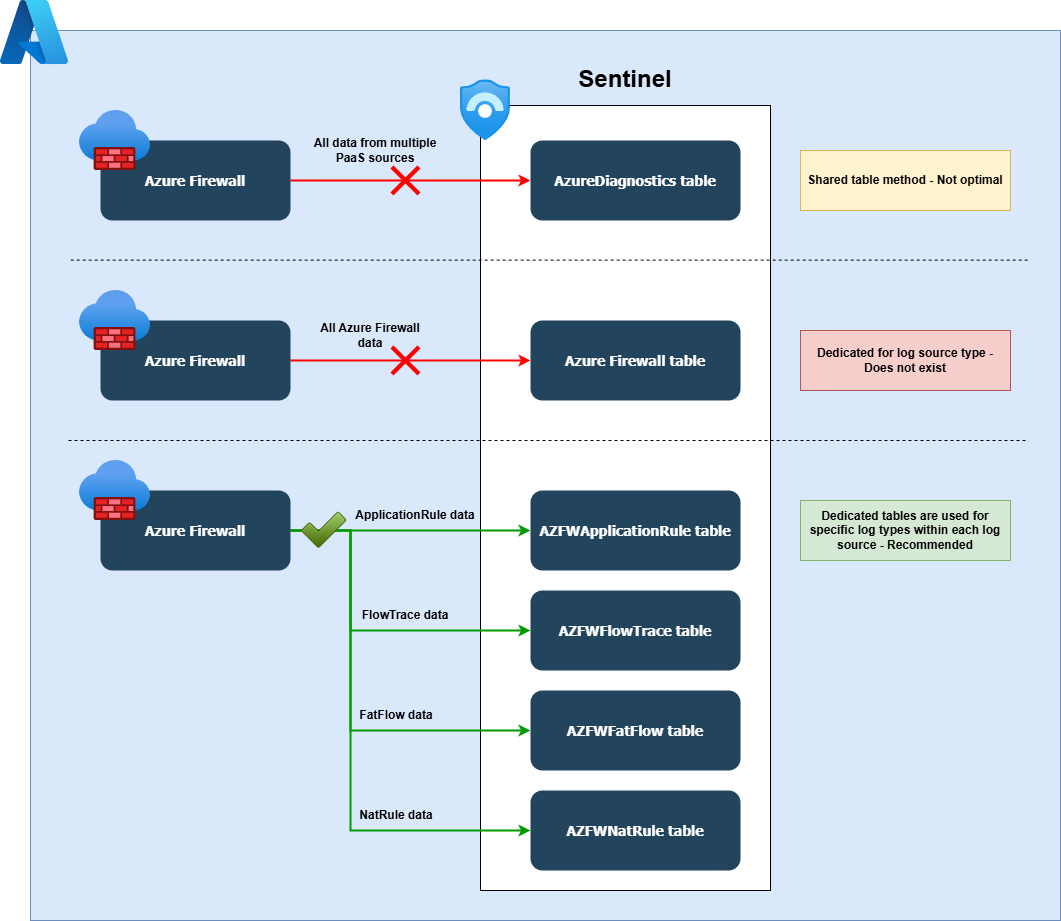 Various theoretical logging options applicable to Azure Firewalls.
Various theoretical logging options applicable to Azure Firewalls.
This granular structure offers several benefits. Instead of consolidating all Azure Firewall logs into one table, each log type is stored separately. This improves query performance and parser efficiency since parsers and data models typically target specific log types. For instance:
- The DNS data model would only query the AZFWDnsQuery table.
- The THREAT data model would focus solely on the AZFWIdpsSignature and AZFWThreatIntel tables.
Applying this principle to other systems, such as Palo Alto firewalls, you could create separate tables like PaloAltoTraffic_CL (for general network logs) and PaloAltoThreat_CL (for IDS/IPS logs). This separation allows you to:
- Target specific data more effectively with parsers and queries.
- Optimize storage costs by keeping high-value logs (e.g., threat detections) in the Analytics tier while storing lower-value talkative logs (e.g., traffic data) in the Auxiliary tier.
- And addresses the other challenges mentioned earlier.
The Auxiliary tier comes with significant limitations, so it’s important to fully understand your specific use cases before deciding to use it for certain types of data.
This granular approach balances performance, cost-efficiency, and usability, making it a more scalable solution for log management in Microsoft Sentinel.
Recommendations
AzureDiagnostics: For AzureDiagnostics logs, the options are limited. Microsoft either provides a dedicated table setup for a specific PaaS resource or does not yet support it. However, Microsoft recommends using dedicated tables whenever they are available mentioning these benefits (for Azure Firewalls):
 Benefits of dedicated tables for Azure Firewall according to Microsoft
Benefits of dedicated tables for Azure Firewall according to Microsoft
Syslog/CEF: For Syslog and CommonSecurityLog, the default approach remains storing all logs in shared tables. This is likely recommended because it simplifies setup and leverages years of existing content built around these tables. However, if you are starting a new Sentinel deployment, I recommend going with dedicated tables due to their added benefits. Keep in mind that this approach may require additional architectural planning and some effort to adapt content during deployment.
The benefits of log separation are illustrated in the diagrams below. As log separation becomes more refined, data models (parsers) process smaller volumes of data, focusing only on what’s required. Thist also enhances other table-level operations, such as granular tier selection or RBAC configurations.
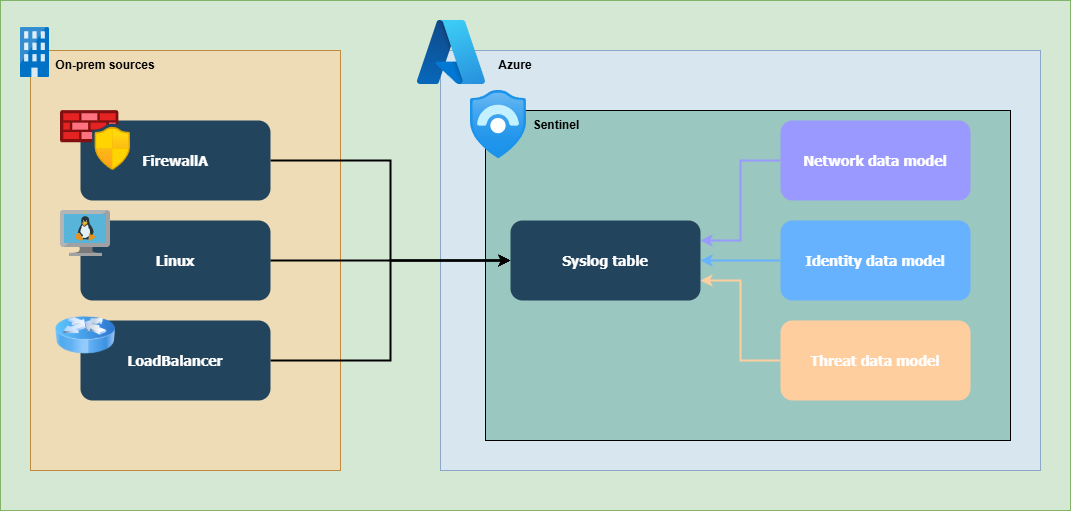 1. Using the shared Syslog table, the parser must query all available data. All three data models have to query all the data in the Syslog table.
1. Using the shared Syslog table, the parser must query all available data. All three data models have to query all the data in the Syslog table.
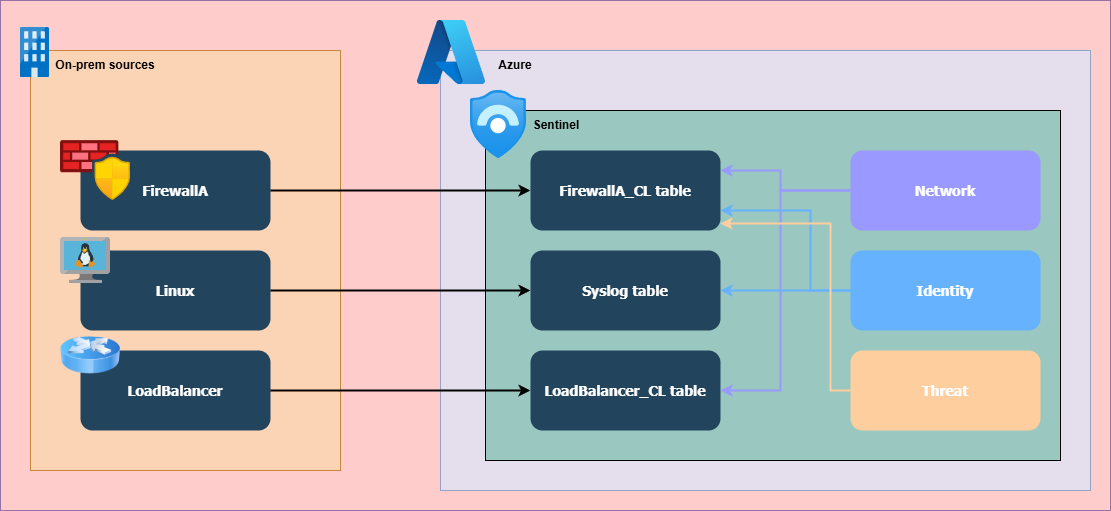 2. Log-source-based separation increases efficiency by reducing the volume of data processed, though parsers still retrieve some unneeded information. All three data models must query the FirewallA_CL table, while other tables are accessed only when their specific data is required.
2. Log-source-based separation increases efficiency by reducing the volume of data processed, though parsers still retrieve some unneeded information. All three data models must query the FirewallA_CL table, while other tables are accessed only when their specific data is required.
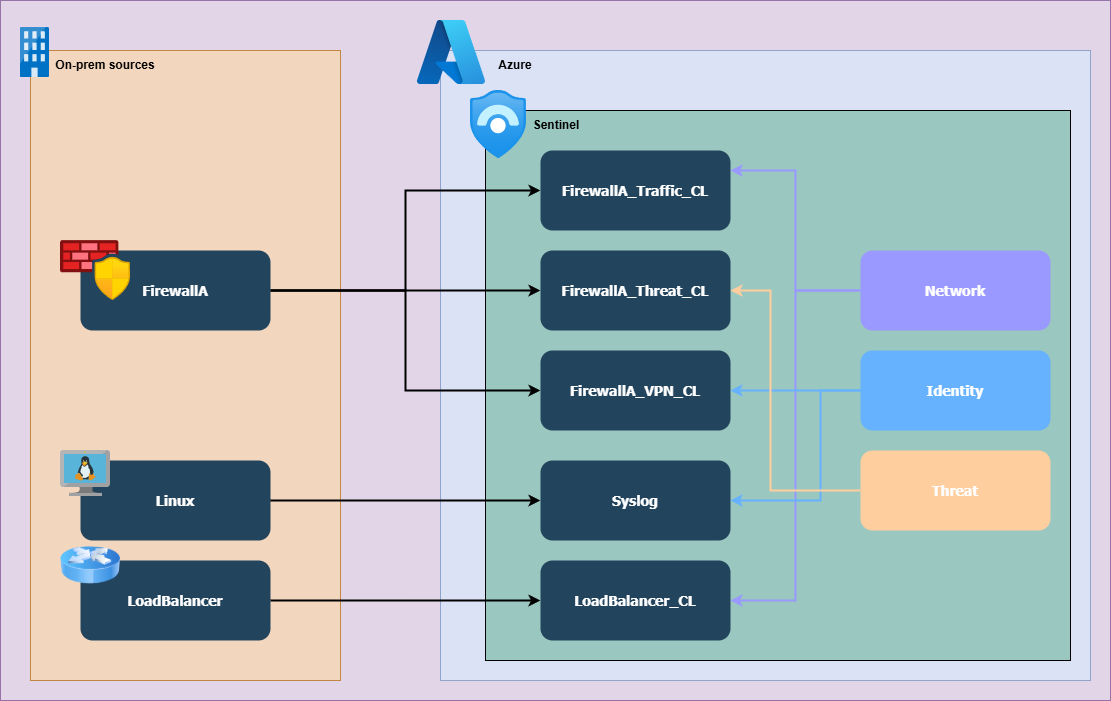 3. Log-type-based separation allows you to significantly reduce the volume of data queried, improving efficiency. Each data model targets only the data it actually requires.
3. Log-type-based separation allows you to significantly reduce the volume of data queried, improving efficiency. Each data model targets only the data it actually requires.
Summary
Transitioning from the default best-practice configuration to a dedicated table-based setup requires thoughtful architectural, design, and engineering efforts. While there are challenges involved, for most companies, the benefits outweigh the drawbacks.
Before making the move, consider the following:
- Create a detailed migration plan that adapts your content to the new setup (and don’t forget about Microsof’s extensible ASIM model).
- Ensure your team, partners, and tools can support a non-standard configuration.
- Identify Sentinel features that might be impacted and assess their criticality for your operations.
- Develop a clear log source and log type separation method. If content-based separation isn’t feasible, consider segregating at the collection level (for example, by forwarding logs to different ports or syslog collectors). Keep in mind that this approach can be challenging with large number of raw syslog-based data sources.
When to avoid making the switch:
- You rely extensively on built-in functions or content that cannot be easily migrated or abandoned.
- You lack a clear understanding of the implications and the effort required.
- Your team, partners, and tools cannot support this setup - and you cannot leave them behind.
- You don’t care about anything in life.
I have worked on Microsoft Sentinel deployments where a dedicated table-based logging setup was already in place, but the surrounding infrastructure, processes, and content were not properly aligned to support this configuration. I have also collaborated with organizations to transition from the default shared table setup to a dedicated table-based architecture, ensuring their systems and workflows were optimized for the change. If you require assistance with designing your initial architecture or managing the deployment process, feel free to reach out.
Remember, the ‘best practice’ is not always the best for your unique requirements.