
In today’s cybersecurity landscape, data models are crucial - they give data the structure and context it needs to be truly usable and effective. Standardized models act as a universal language, turning raw security data into actionable insights for rapid detection, efficient investigation, and precise response. Choosing the right data model is essential for both traditional SOCs and advanced AI-driven security platforms that require structured, normalized data for accuracy.

This post provides a general overview of the benefits of a data model and the challenges you may encounter using AI tools without one. In the next article, I’ll share hands-on experiences and useful guidelines to help you prepare for the future.
Data Model
So, then what is a data model?
A data model is a structured blueprint that defines how information is organized, stored, interpreted and related within a system. The data model acts as a translation layer that converts the various formats into a unified structure. It transforms the data into information. For example:
- A firewall might log a blocked connection as “connection_denied”
- An application might record the same type of event as “access_refused”
- A user can try to unsuccessfully access a resources logged as ‘access_denied’
- The data model normalizes both into a standard field like “result=blocked”
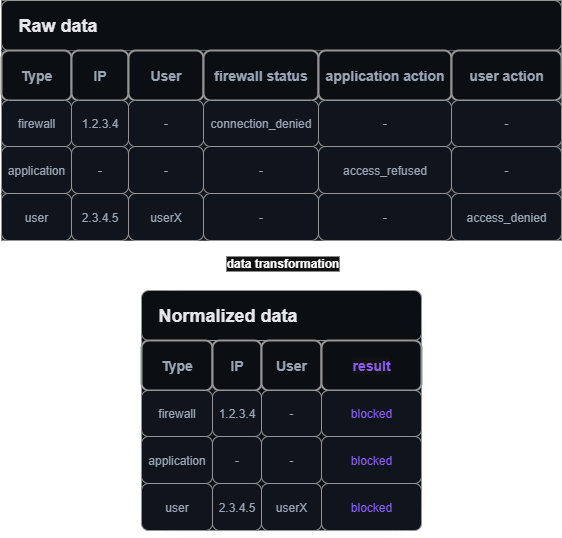 Data normalization
Data normalization
Without a data model, the vast diversity of log formats creates major challenges:
- Detection engineers must create and maintain multiple variations of detection rules for different formats, slowing rule deployment and reducing coverage.
- SOC analysts face inefficient investigations and alert fatigue due to inconsistent data, making it harder to correlate events and respond quickly.
- AI models suffer from poor data quality and increased preprocessing complexity, which undermines detection accuracy and automation potential.
Keep in mind, having a data model doesn’t require parsing and normalizing data at ingestion. Security logging often centralizes data in cost-effective data lakes, which typically use a ‘Schema-on-Read’ approach. This means raw data is ingested without fixed schemas, and schema definitions are applied only when the data is read or analyzed, allowing greater flexibility for semi-structured or evolving data sources. In this case, the data model serves as the rule that tells you how to access the data you need and where to find the necessary information.
Data for human and machine
Some logs may be easy for humans to read but hard to parse effectively. Others are excessively verbose - while the extra detail can help an LLM, it often wastes storage and analyst time. Security teams usually prefer concise, normalized logs that highlight key details. On top of this, some logs require lookup tables to interpret correctly, which makes them difficult for both humans and AI without the right context.
1. Windows Event
Take this simplified Windows 4625 event:
<System>
<EventID>4625</EventID>
<Computer>DC01.contoso.local</Computer>
</System>
<EventData>
<Data Name="SubjectUserName">DC01$</Data>
<Data Name="SubjectDomainName">CONTOSO</Data>
<Data Name="TargetUserName">Auditor</Data>
<Data Name="Status">0xc0000234</Data>
<Data Name="FailureReason">%%2307</Data>
<Data Name="SubStatus">0x0</Data>
<Data Name="LogonType">2</Data>
<Data Name="WorkstationName">DC01</Data>
</EventData>At first glance, the fields hint at a failed login but don’t explain why. Extra knowledge is needed:
- Event ID 4625 → failed Windows login
- Status 0xc0000234 → account lockout
- LogonType 2 → interactive logon attempt
A data model lets you store events in their raw format - for example, using only codes in Windows Event logs - but through enrichment, you can assign easy-to-understand values to them. With a parser, logon type 2 can be translated to ‘interactive logon’ for analysts, and similarly, less common log types can be made understandable for AI processing.
2. Cisco Log Example
Now let’s look at a Cisco log:
Error Message %FTD-7-715019: Group group Username username IP ip IKEGetUserAttributes: Attribute name = nameCisco logs tend to be pretty talkative, but just by looking at this one I cannot be completely sure what it means. That said, pulling out fields like the Group, Username, or IP address looks fairly straightforward. Instead of doing it manually, I asked a couple of AI tools to generate a Cisco FTD parser in KQL, with the parsed field names made ASIM-compliant, using my sample log as input.
First result:
CommonSecurityLog
| where DeviceVendor == "Cisco" and DeviceProduct has "FTD"
| extend RawMessage = coalesce(Message, AdditionalExtensions)
| where RawMessage has "FTD-7-715019"
| extend
UserGroup = extract(@"Group\s+([^\s]+)", 1, RawMessage),
TargetUsername = extract(@"Username\s+([^\s]+)", 1, RawMessage),
SrcIpAddr = extract(@"IP\s+([^\s]+)", 1, RawMessage),
IKEAttributeName = extract(@"IKEGetUserAttributes:\s+Attribute\s+([^=]+?)\s*=", 1, RawMessage),
IKEAttributeValue = extract(@"Attribute\s+[^=]+\s*=\s*(.+?)(?:\s|$)", 1, RawMessage)
| extend ActorUserName = TargetUsernameSecond result:
Syslog
| where SyslogMessage contains "%FTD-7-715019"
| parse SyslogMessage with "%FTD-7-715019: Group " TargetUserGroup " Username " SrcUsername " IP " SrcIpAddr " IKEGetUserAttributes: Attribute name = " Attribute
| extend EventType = "IKEGetUserAttributes"It’s easy to see the problems:
- Field mapping differences: One parser labeled values under different field names (e.g., Group vs. UserGroup). Each AI interpreted the log differently depending on training and input.
- Table mismatch: They generated queries against different tables, so only one would actually work in my environment.
- Cisco log variety: Cisco logs vary a lot in format, so a single sample log isn’t enough to build a universal parser or to even cover your critical events.
In the case of Cisco logs, a data model ensures that both analysts and AI query the correct tables and access the requested information through standardized common fields.
AI querying your data
In most environments, you’ll have hundreds of gigabytes or even terabytes of data to analyze, and you need to assist your AI in processing it effectively.
For example, when you ask your LLM to show all login attempts by ‘userX’, the system first needs to gather that data. This can be done by letting the LLM understand a logfile on its own - without additional context - and read through it. LLMs excel at searching data, understanding it and providing answers, so feeding them a small logfile of a hundred lines even without context works well.
However, with terabytes of data, expecting your AI to scan every event individually just to find a few relevant ones is unrealistic. For an AI assisted SOC tool investigating all the incoming incidents, this approach would be slow, extremely costly in terms of AI token usage, and expensive due to data query charges - if you use a data store where querying is not free.
Practical recommendations:
- Structured logs and uniform data: For these logs, use AI to generate extraction scripts or parsers. This streamlines normalization by automating field mapping and reduces manual effort, ensuring consistent, accurate data transformation. Instead of processing all the data, have AI generate a script to collect the needed information and then work solely on the results. (Initial AI use only)
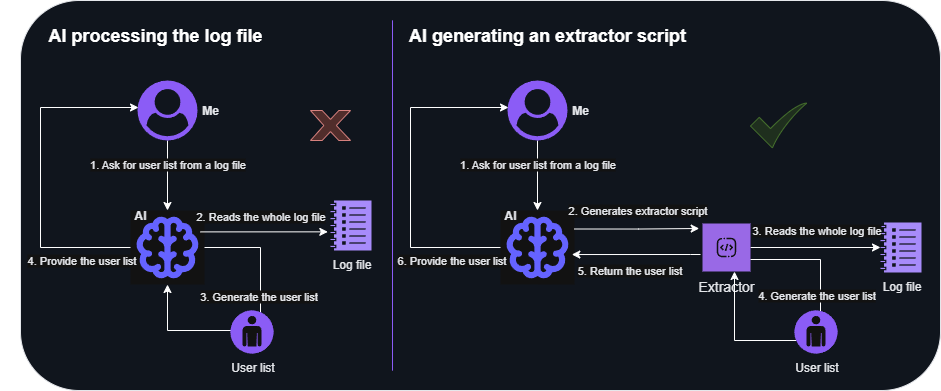 AI file read scenarios
AI file read scenarios - Unstructured or heterogeneous logs: AI excels at finding information in logs where a general parser would fail. When there is no clear structure you can use AI to extract the information you need. (Constant AI usage)
- Hybrid approach: Ask AI to create a script based on sample data, then gradually process all logs using those scripts. Let AI identify unparsed or unrecognized data and either create parsers on-the-fly or extract the necessary information ad hoc without static parsers. (Initial AI use, then occasional invocation)
This is the reason why your AI tool typically does not process all the data directly but is trained to generate queries to retrieve the required information. However, this approach has some prerequisites:
- Your AI tool has to be familiar with the query language - this is typically not a problem.
- The AI needs to understand your environment’s data format - problematic if it’s non-standard:
- You can provide data details like table names, schemas, and log identifiers. It may also need metadata explaining each field to correlate different log sources effectively.
- Alternatively, use a well-known data model and tell your AI to follow it; most AI solutions are already familiar with these. In this case, adding a new data source covered by the data model could be completely transparent to your AI.
Brute-force attempt prompt
Let’s see how an AI tool would approach detecting a brute‑force attempt if my prompt only asked it to create brute‑force detection logic in KQL.
SecurityEvent
| where TimeGenerated > ago(1h)
| where EventID == 4625 // Failed logon attempts
| summarize FailedAttempts = count() by Account = TargetUserName, SourceIP = IpAddress, bin(TimeGenerated, 5m)
| where FailedAttempts >= 5 // 5 or more failed attempts in 5 minutes
I hadn’t specified my log sources, so the AI defaulted to creating a query for Windows machines only. After I added Entra ID and Okta, it generated separate queries: one for SigninLogs and one for OktaSSO. The Okta query worked - assuming the OktaSSO parser was deployed - but I couldn’t get it to cover other Entra ID tables without explicitly asking for them.
A simpler way was to have the AI build the rule using the ASIM model. That instantly produced one query working across all authentication log sources, as long as ASIM-compliant parsers and the custom ASIM function were configured.
// ASIM Authentication Brute Force Detection
let BruteForceThreshold = 5;
let TimeWindow = 5m;
let LookbackTime = 1h;
_Im_Authentication(starttime=ago(LookbackTime))
| where EventResult == "Failure"
| summarize
FailedAttempts = count(),
by TargetUsername, bin(TimeGenerated, TimeWindow)
| where FailedAttempts >= BruteForceThresholdA well‑defined data model streamlines AI processing and improves reliability.
Data Model Approaches
To really benefit from a data model, every log source needs a parser. Without one, you risk gaps and inconsistent results. Creating the data model framework along with the parser code can be a significant effort, so choose your approach carefully based on your current needs and future goals.
There are several ways to approach this:
- Build your own custom model: Offers full control and maximum flexibility, but requires significant effort to design, implement, and maintain.
- Use your SIEM’s native schema: For example, Microsoft Sentinel’s ASIM provides structured normalization out of the box. This is often easier to adopt, but usually only works within that specific SIEM/tool.
- Adopt a public standard: Frameworks like the Open Cybersecurity Schema Framework (OCSF) offer clear documentation and community parsers for common data sources, so you can get started quickly. OCSF is widely supported across vendors, though Microsoft does not currently use it.
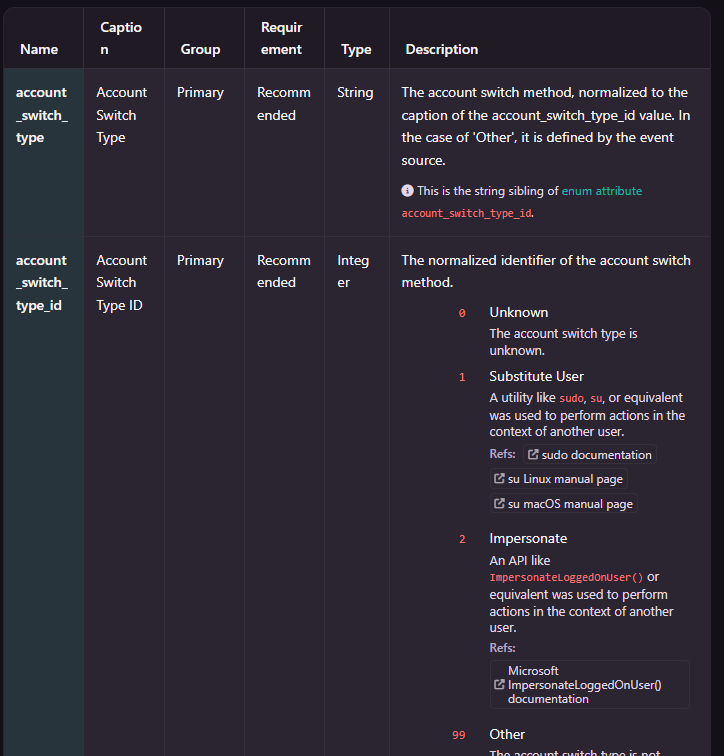 A sample data type of OCSF - authentication class
A sample data type of OCSF - authentication class
As noted, LLMs need two key elements for query generation:
- Knowledge of the query language (KQL is already well understood by public models).
- Understanding of the data format and content. With well-known models like OCSF or ASIM, training your AI may not be necessary. However, for less common models or to provide more context for better accuracy, you need to teach your AI your specific expectations.
Choose the option that best suits you and your environment, and remember that providing additional contextual information can always enhance your AI’s performance.
Coming up next
I work on a variety of AI‑enhanced solutions, most of them dealing with data - whether it’s parsing, processing, or handling it - at scale. One pattern I’ve noticed over and over is that without a mature data model, proper parsers for each source and useful metadata, data processing quickly becomes painful.
In my next post, I’ll share some practical recommendations from a data architecture perspective - especially useful if you’re just setting up your logging infrastructure and want to make your data easier to leverage with AI.
For now, keep in mind that the examples above work well when your AI tool can access data already aligned with the target data model. If it first has to query raw logs, adjustments may be needed. I’ll walk through this in more detail in the next post.