I have recently started to make some basic research with osquery. I investigated some malware infections in the past and I decided that I’m going to take a look at them with osquery as well. I was curious how much data I can retrieve with osquery and how much I will benefit from its usage. I was honestly surprised because it helped me make some basic information gathering faster than my earlier methods. I would recommend anybody to take a look on osquery if they don’t know it yet. However, this post is not going to be about the usage or setting of osquery.

During my investigations, I encountered some repetitive and re-occurring tasks and I wanted to automate them. My first idea was to generate an output that can show me a clear parent-child relationship for the processes but unfortunately osquery is not able to do that by itself. After I created a simple script to solve this issue, I decided to move forward and try to use the provided information by osquery as efficiently as I can. I built in some automatic analyzing function into my script which can detect different malicious behavior. In this writing, I’m going to tell you why I decided to check the maliciousness the way I did, how my script can be used in case of smaller investigations and how it can be beneficial for you to write your own.
Download my processAnalyzer.py script from github.
Osquery
There are a bunch of basic tutorials and installation guides for osquery out in the wild. Therefore I’m not going to write about these topics. Rather in medias res, I’m starting with the explanation of the osquery query I used for process investigation.
The first table I used is the processes table. This table contains detailed information about the running processes like their name, path, startime, etc. The following request is going to provide the running processes with some information. The ‘pid’ is the process ID which is needed to identify the parent of the processes. The process only contains the pid of its parent (parent) but not its name or path, so this is the information I can use to correlate the two processes. For example, if a process has a parent ‘2345’ then I can look up the collected data to find a process thats pid is ‘2345’. That is going to be the parent of the given process. The other significant information fragment is the on_disk value. This is going to tell us whether the file of the executed process is still on the disk or not. Various malwares try to hide their presence by removing their binary from the disk after execution.
SELECT pid, name, path, parent, cmdline, start_time, elapsed_time, on_disk FROM processes Another useful table is the hash table of osquery. By using this table one can collect the hashes of the specified files. Be aware though that this can’t be executed without a “WHERE” statement. Instead of storing them, this table calculates the hashes of the referenced files on-the-fly. Without any constraints, this table will not know which files to generate the hashes for so it will return with no results. (Generating the hashes for every file on the machine would be too much for the system.) So this is what a query which is going to return with the hashes looks like:
SELECT md5, sha256, path FROM hash path LIKE '/Users/test/Downloads/%';I joined these two queries together to be able to collect the running processes with their hashes (if their binary is still on the machine). To join two queries together I needed to choose a parameter which can be found in both tables. In my case, this parameter is the path parameter which is the location of the binary that was executed. So my query is going to work the following way: ossquery collects every running process from the machine. Then checks the paths of the binaries (if they are still existing) and calculates the hashes for them.
SELECT p.pid, p.name, p.path, p.parent, p.cmdline, p.start_time, p.elapsed_time, p.on_disk,
h.md5, h.sha256 FROM processes p LEFT OUTER JOIN hash h ON p.path=h.path;In that final query, I used LEFT OUTER JOIN. This means every value is going to be used from the left table (processes) regardless of the values from the right table (hash). If there is a match in the hash table for the entry from the processes table,those are going to be joined. If there is no match, so there is no hash for a process, the values from the processes table are still going to be used but the values from the hash table are going to be empty string/values.
Here is an example for the LEFT OUTER JOIN when the hash couldn’t be calculated. The last two attributes are empty, those are for the hashes according to the first title row.
pid|name|path|parent|cmdline|start_time|elapsed_time|on_disk|md5|sha256
0|"System Idle Process"|""|0|""|-1|132021941279056622|-1||And here is an example when the hashes could be calculated.
pid|name|path|parent|cmdline|start_time|elapsed_time|on_disk|md5|sha256
648|winlogon.exe|C:\Windows\system32\winlogon.exe|544|winlogon.exe|-1|132021939728929986|1|749ca1f1b638e4e4a8a1f0990377012f|823ae63ba5fca8aebaffffc52ed32c4c128ab4801e59a220688460a6b3a1a43bAn osquery script can be executed from cmd/powershell directly to write the output to a file. This way you don’t have to log into the interactive osquery console (osqueryi).
osqueryi.exe -csv "{osquery_command}" > output_file.csvAnd this is the csv output we are going to parse and investigate in the script.
The script
So I have written a script to investigate the maliciousness of processes based on the previously described osquery command output. The script can be downloaded from github. It is still under development but feel free to download it and modify it as you want. There are two arguments which are mandatory for the script to run. The first one is the input which contains the csv output of osquery with the necessary fields. The second one is the mode argument which defines the behavior of the script.
JSON mode
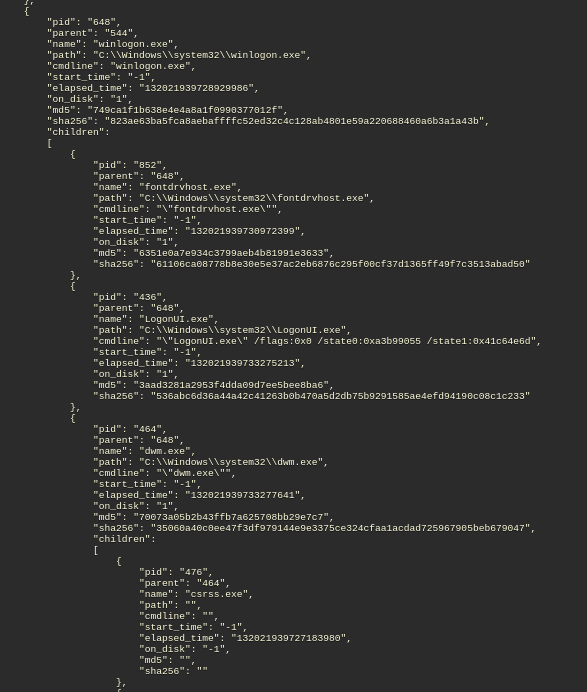
The script has three different modes right now. You can choose this mode with the –mode switch. The first one is the “json” mode which is only going to generate a json output from the csv one and it is going to show the proper child-parent relationships. It is easy to check the mentioned relationships manually in json format because it can be easily interpreted by humans as well. Here is an example json output:
LEARNING mode
The second mode is the “learning mode”. This one can be turned on by executing the script with the “–mode learning” switch. This mode was generated to create a baseline process list for later analyzis. In learning mode, the script reads every running process from the input file and saves it into the known processes file. The filename for the known processes can be set with the –processfile switch otherwise the default (known_processes.json) is used. If the provided process file already exists with known processes in it, the given entries are also going to be updated during the learning execution.
The learning mode was created so you won’t need to predefine a known processes list beforehand. On the other hand, it is worth to use the provided default list because it contains some basic Windows processes. You can also execute the osquery script on your machine multiple times and then feed the results to the script in learning mode. This will create a baseline list (benign process list) for you. If you are sure your machine is not infected, you can use this method to generate a list instead of the provided one. Every loaded process with their information (parent, path) is going to be handled as known benign after the learning phase.
About the known_processes.json file. This file is a json file, in Python it is represented as a list of dictionaries with 4 value in them. The first value is the “name”, which is obviously the name of the process. The second one is a variable named “number”. This defines how many instances can exist of that process at the same time. “1” means only one can exist and “2” means there can be more than one. The third value is the “location” which is a list that contains the possible benign locations. The "" value means that we are ok if osquery can’t find the location while an empty list means the location can be anything, we don’t want to investigate it. The last element in the dictionary is the “parent”, which is also a list and it behaves the same way as the location. Here is an example of a simple known_processes.json file with 2 entries.
[
{
"name":"csrss.exe",
"number":"2",
"location":["%SystemRoot%\\System32\\csrss.exe",""],
"parent":["smss.exe",""]
},
{
"name":"smss.exe",
"number":"1",
"location":["%SystemRoot%\\System32\\smss.exe",""],
"parent":["System",""]
}
]In the example above we can see two entries, one of them is smss.exe. After this we expect every smss.exe to work the following way: it can only have 1 instance in the input file, its location has to be %SystemRoot%\System32 if it was found by osquery and its parent have to be System, if it was found by osquery. Be aware that in learning mode only name, location and parent is going to be filled based on the input while the number is going to be set to 2 in every occasion.
ANALYZE mode
The third mode is the cream of the script. It analyzes the provided process list with multiple functions. The script can use a pre-defined process list or the output of the script in learning mode as the basis of comparison. A well-defined list of known benign processes is important because these are going to be compared to the running processes.
I implemented seven functions for the analyzis mode:
- Amount of processes with the same name - based on the number variable in the known processes list
- Location of the executed process - based on the location in the known processes list
- Parent of the executed process - based on the parent in the known process list
- Similarly named processes - based on the known process list
- Whether the binary is still on the disk or not - based on the on_disk value of the osquery output
- Recognize randomly generated paths - turned off, not reliable yet
- Process hash check on VirusTotal
The next chapter is going to describe the reliability and behavior of these methods.
Reliability of the analyzation functions
I implemented 7 different methods to identify odd service behavior based on the csv output. Their requirements and reliability are different so I’m describing each one of them separately. In some cases, these functions can generate False Alerts. Thus, a process can be marked as suspicious even when it is a clean one. The amount of FPs can be decreased by modifying and fine-tuning the required inputs by the script. It is going to be your job to adjust the input to your environment if you want to use the programme. (Some of the adjustment can be done by running the script in learning mode.)
1. Amount of processes of the same name
The first method I used is trying to identify uncommon behavior based on the amount of the processes with the same name. Some native Windows processes are only executed once. Therefore, only one instance can exist at the same time. This function looks for processes which should only have one instance but in reality, they have more. This generally means a malicious entity executed the same process again for malignant reasons or it copied a Windows process name to try to hide. So, in this case, the plain fact that a process name can be found multiple times is suspicious enough to investigate it further.
For this, of course, we need a baseline process list which contains the processes which can only have one instance at a time. I used the SANS’s Find Evil poster to gather some processes for this. This counter can have two different values. “1” means it can have only one instance and “2” means it can have any number of occurrences. The script is only checking the ones with the value of 1 and reports if there are more than one of them.
The chances of false alerts for this function depends on the baseline process list we are providing to the script. If it is filled properly, then false alert almost never will be generated. The only situation it can generate an unnecessary alert is when the user executes these processes by him/herself for testing or similar purposes. Since these are Windows-related processes, executed by Windows itself, no other process should execute them by itself.
Example: There should be only one wininit.exe running on Windows. If there are multiple of them it raises suspicions.
2. Location of the executed process
The second way to find suspicious processes is to check their execution directory. The script is going to compare the executed processes to the provided baseline process file. So again, this is something that only works if we have a well-defined list we can give to the script. This is also mostly useful in case of native Windows processes but it can be used too, if you are collecting every process on your machine frequently. Lots of malwares copies the name of a Windows process to evade detection by security analysts. Since two files with the same name are not allowed in the same directory, the attacker/malware generated one is not going to be in its usual place. The path of the normal Windows processes are well-known so these are easy to check. For every other file, you have to update your baseline process list so the script can look for those files as well. For example Chrome is not part of a default Windows installation, but since it can be found on a lot of machines, a malware will happily try to copy its name.
This is a pretty reliable rule but in some cases, it can generate false alerts. The reason behind the FPs is the fact that anybody can use almost any string as a name in Windows. So any name owned by a Windows process can be used by any other software as well in different directories. Therefore this method also needs some fine-tuning from your side.
Here is an example I found during my tests. Part of the output of my script:
Name: svchost.exe
Location: C:\ProgramData\WmiAppSrv\svchost.exeThe real path for svchost.exe should be “%SystemRoot%\System32\” a.k.a. “C:\Windows\System32\svchost.exe” but this svchost.exe was executed from: “C:\ProgramData\WmiAppSrv\svchost.exe”. Definitely suspicious.
3. Parent of the executed process
This is similar to the first one. It can be used mostly for Windows processes. It is going to generate an alert if the parent of a given process is not the expected one. For example, we know that the parent of services.exe should be wininit.exe and the parent of wininit.exe should be smss.exe. Any digression is immediately suspicious. Unfortunately, this method is not too reliable. Every process saves the ID of its parent but not the name or path of it. Since IDs are re-used in Windows this can mean that during a check the process that uses the given ID is not the one who used it when the child was started. Therefore the process behind the parent ID is not the real parent. Also in some cases, the parent is not retrievable either because it exited or simply osquery is not able to collect it.
Since this method is false-alert-prone I’m only using it as a supplementary rule.
Example: The parent of svchost.exe on a Windows machine should be services.exe. Any other parent is suspicious. ( The current version of the code only checks the name of the parent but not the full path.)
4. Similarly named processes - masquerading
Sometimes the attacker doesn’t want to copy the Windows process name and execute it from a different directory but rather tries to execute a script from the same directory and name its executable similarly. For example, instead of running svchost.exe it runs scvhost.exe. This way it can evade human detection. It uses the natural behavior of our brain, that we easily misread “typos”, against us.
For this, I used the difflib Python library’s SequenceMatcher function. This function returns with a value of how different the two strings are. In my code, I’m comparing the recently tested process name with the known baseline process names and trying to find similarities. Again, this is mostly useful when the baseline process list contains Windows processes, but we can fill it up with others as well.
Here is the script that goes through the known processes (known_processes) and compares their name to the actually tested one (process_name). The comparison function generated a value which I transformed to a number between 0 and 100. If the similarity is higher than 90 but they are not the same (100) then I’m marking it as suspicious. The 100 means they are the same, so it is either a normal Windows process or the second method is going to alert. The value 90 was defined based on my testing and can be modified if needed.
for process in known_processes:
sequence = difflib.SequenceMatcher(None, process_name, process['name'].lower())
ratio = sequence.ratio()*100
if(ratio > 90 and ratio < 100):
generateAlert()The reliability of this alert is mediocre. Similarly named files can be used by any other processes in a non-malignant way. Also, this can be tuned by setting the ratio value. Decreasing it will generate more FPs, increasing it will generate more False Negatives. It is up to you to adjust it.
5. Executable is still on the disk?
Malwares can try to hide their existence by removing the original binary from the disk after execution. Most of the AV tools are only checking files on the disk but they are not checking memory or registry for example. A malware can execute itself from the disk and then it can delete the file. This way the AntiVirus solution won’t be able to check and identify the file. This is a well-known action by malwares and it is actually checked by a lot of EDR systems. Also, it is not unusual in forensics that the analyst checks the existence of origin of the process on the disk. But my script and osquery are still cheaper than an EDR.
The benefit of this method is that it doesn’t need any other input data like the baseline process list does. Only the osquery output (process list) is needed for this. The osquery output for the on_disk variable can take three values. -1 means osquery couldn’t gather this information, 0 means the file is not on the disk anymore (suspicious), 1 means osquery found the file on the disk.
This can be tested from osquery with a simple query:
SELECT name, path, pid FROM processes WHERE on_disk = 0;But since it has already been gathered for my script, I just used a simple if statement:
if(proc.on_disk == 0):
generateAlert()6. Recognize randomly generated paths
Malwares frequently generate their location or even their names randomly. During every execution, they generate a new path/name, create a file there and execute it. This way it is much harder to get rid of the infection. For an analyst it isn’t that hard to recognize randomly generated strings. However, it is a little bit harder to do it programmatically. To implement this function I used Shannon entropy. It is good for discovering the statistical structure of a string. Technically, it counts the information value of an input. Unfortunately, this is not that reliable when it comes it short strings.
I tried this method in multiple ways, using the full path, checking every folder in the path one by one but I still did not get a reliable function. Due to the high amount of False Positives and False Negatives I turned off this solution, it is not in the code right now. If I can fix this somehow, or I can find a steadier algorithm, I’m going to implement it and turn this method on.
Example: WannaCry created a tasksche.exe in a randomly named directory. E.g.: C:\ProgramData\nslvfbryqv823\tasksche.exe. Unfortunately this method is not working right now.
7. Process hash check
If you provide an API key in ‘analyze’ mode to the script, it checks the found hashes on VirusTotal. The speed of the lookup depends on the type of your key. The free tier submission allows only four hash retrievals per minute. While it can be slow, this is the most reliable method, at least FP-wise. If a hash is recognized as malicious, then due to the properties of an MD5/SHA256 algorithm, the chance that the related file is benign is almost non-existent. On the other hand, the chance of a false negative is way higher. FN can be caused by a malware that can change its own code (since it will change its hash), or by any new malicious code which hash is not known yet.
The code for this is pretty simple. I’m retrieving every hash from VT. The HTTP status code 200 means the request was successful so I’m only moving forward if I get this value, otherwise, I’m waiting. After that I’m also checking the VirusTotal response code (which is not equal with the HTTP status code) to ensure its value is 1. 1 means the hash gathering is successful and 0 means it is unsuccessful. There are no further checks, so if something is unsuccessful my programme does not upload the file, it does not ask for rescan, it either gets a value or not.
Some of the used AV vendors on VirusTotal are not completely reliable though. Because of this, I’m only marking a hash malicious if at least 5 vendors say it so. During lookup, I’m also generating a cache, so the same hash doesn’t have to be checked multiple times. Here is some code snippet for this:
while(not done):
url = 'https://www.virustotal.com/vtapi/v2/file/report'
params = {'apikey': apikey, 'resource': hash_a}
response = requests.get(url, params=params)
if(response.status_code != 200 ):
time.sleep(30)
else:
done = True
response = response.json()
if(response['response_code'] == 1):
hash_cache.append({'hash_a':hash_a, 'positives':response['positives'] \
, 'total':response['total']})
if(int(response['positives']) > 5):
generateAlert()Testing
And here comes the most interesting part of the post. I tested my script on known malwares and suspicious files. I installed the real infections to a VM, executed them (with turned off Windows Defender) and I saved the running processes with the osquery command.
Testing on a malicious miner
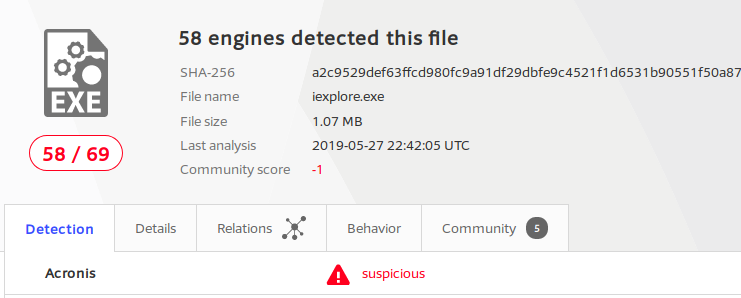
I downloaded a monero miner with the hash of a2c9529def63ffcd980fc9a91df29dbfe9c4521f1d6531b90551f50a87677c89. The interesting part for me wasn’t its mining behavior though. This miner is trying to evade detection by masquerading its processes to typical Windows process names. By opening the VirusTotal site you can see that the file is named iexplore.exe. This executable tries to look like an Internet Explorer executable while in reality, it has nothing to do with IE.
For testing purposes, I executed the downloaded miner on my machine and a little bit later I ran the known osquery command to gather the necessary information for my script. I used my script in ‘analyze’ mode. The known good Windows processes I used for comparison were the 11 processes from SANS’s Find Evil poster. The script was executed the following way:
python3 osquery.py -i svchost_miner/svchost_miner_22 -f analyze -a -p svchost_miner/known_processes.jsonAnd this is the output my script generated:
PID: 9072
Name: svchost.exe
Location: C:\ProgramData\WmiAppSrv\svchost.exe
Malicious hash: d682cdb6de50fac421c72ecec6c49c8e ratio: 50\62.
Malicious hash: a2c9529def63ffcd980fc9a91df29dbfe9c4521f1d6531b90551f50a87677c89 ratio: 50\62.
Incorrect location. Process location: C:\ProgramData\WmiAppSrv\svchost.exe
PID: 9220
Name: csrss.exe
Location: C:\ProgramData\Microsoft\WmiAppSrv\csrss.exe
Malicious hash: a9a10921ac9b11954b05be7d44b1a250 ratio: 46\67.
Malicious hash: 7b3658d0d0a53607ca22a67a87df33fb55b7c0f4c492260ff03d1063b2ad466b ratio: 46\67.
Incorrect location. Process location: C:\ProgramData\Microsoft\WmiAppSrv\csrss.exe
Incorrect parent.The script identified these two processes as incorrect or possibly malicious. Both of them were recognized as Windows services based on their name but none of them were actually real Windows processes. The Windows processes of the same name should have been executed from the “%SystemRoot%\System32\” directory not from the “C:\ProgramData\Microsoft\WmiAppSrv". This was the first thing my script recognized. Also, their hashes were malicious according to VirusTotal so these files were clearly malicious. Additionally, csrss’s parent should be smss.exe but in this case, it was an svchost.exe. (the parent information can’t be seen in the output.)
Hence the script successfully identified these anomalies:
- Suspicious location (!)
- Suspicious parent (!)
- Malicious hash (!)
Testing on Ave-Maria malware
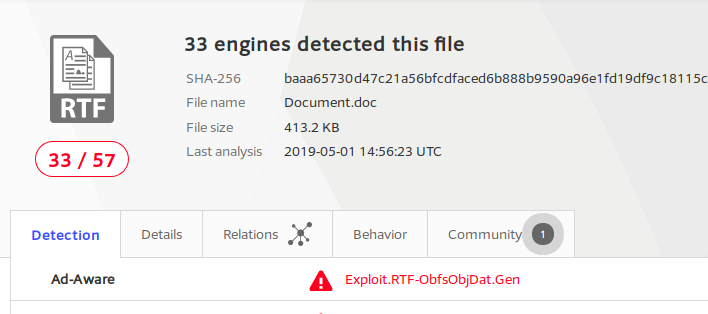
I executed this malware to test my tool. The specialty of this malware is that it tries to masquerade itself by copying and mistyping a Windows executable name. This Windows executable is svchost.exe and the malware creates a file with this name: scvhost.exe (changes the c and v).
Multiple “EDR"s I used reported if a malware created a file with a typical Windows executable name like svchost.exe, but most of them did not do anything in case of a mistyped but still delusive filenames like scvhost.exe.
And this is the finding generated by my tool to the masqueraded filename (this one was generated as a child of the downloaded and executed process):
Adapting. Changing the checkable name from: scvhosts.exe to: svchost.exe .
PID: 10236
Name: scvhosts.exe
Location: C:\ProgramData\scvhosts.exe
Malicious hash: 7ea7a4ba0e7eed5b3d7a2acda835bdbe ratio: 49\67.
Malicious hash: 003fd2404d515bf67c01f632014179414c8f28cfefd18fb5453c05e058825b0e ratio: 49\67.
Possible name alteration: proc name: scvhosts.exe Win proc name: svchost.exe
Incorrect location. Process location: C:\ProgramData\scvhosts.exe
Incorrect parent.The script recognized these oddities:
- Name alternation (masquerading) (!)
- Malicious hash (!)
- Incorrect location and parent are related to the normal svchost.exe files not to the scvhost.exe. So while those are not relevant in case of masquerading, they are still good to know. (?)
Process anomaly detection
I also wanted to implement an anomaly detection function into the script but it hasn’t been done yet. I still made some testing manually without my script. Unfortunately, this anomaly detection should have been done on a Windows machine but I’m not using that OS right now. Thus I made the test on a test VM of mine. Because of this, the test is not that comprehensive so I’m not going to share the test itself only the idea behind it.
So the base of the idea was the LEAP - Localized Encryption and Authentication Protocol’s key distribution mechanizm which are used in WSN (Wireless Sensor Network) environments. There are two main assumptions of this function in LEAP. The first one is that an attacker will need at least T_min time to compromise a sensor node. And the second one is that every node can discover its neighbors and share the keys in T_est (few seconds) time. The idea is that T_est < T_min and every key distribution and possible unsecured communication should happen in T_min. At T_min time some of the stored keys are going to be removed and every communication is going to be secured so if one node has been compromised the others will be still safe.
I wanted to apply this to computer networks in a company environment. So these were my main assumptions:
- The computer is safe for at least T_min time after its installation.
- The administrators and the user who’s going to use the machine can set it up in T_est time and T_est < T_min. These times were just seconds in case of LEAP but are going to be way higher in this computer-based implementation. So T_est < T_min is not trivial.
So how can we assure that the user is not going to install anything malicious before T_min time?
I would recommend to define the T_min not as a timer but rather as a phase counter with the following phases.
- Installation phase: In this phase, the machine and basic (mandatory) tools are installed. If the installation media is clean, the machine can be considered clean after the installation. Every process that was generated on the machine during and after this can be handled as benign.
- Tool installation based on user’s role: Many companies deliver the machines to the user with tools pre-installed on it. In this phase, the administrator/helpdesk installs the tools which are required by the user based on his/her role. Like the company approved IDE for a developer. This step can also be considered safe because these installations normally happen from an internal repo and from approved sources. (Of course these can be compromised as well, but then the problem is much bigger.)
- Restricted user access: In some companies, the user won’t have every accesses from his/her start date but the user has to request accesses. We can enforce this phase by giving the user access to the internal network but not to the internet. The user can install every other tool he/she needs from internal repositories and sites. The security of this phase depends on what we consider malicious and what accesses we give to the user. For example, we can consider internal mails as a threat because it can contain malicious files. In this case, this phase is at least semi-insecure. If we consider this phase safe then this going to be the T_min. Every process generated in this or before this phase will be considered benign.
- Unrestricted access: The user has every accesses (of course with applying the least privilege principle) so he can install everything he wants.
We can consider the first three steps safe. We can save every running process with its name, parent and path and upload it to a central storage. These processes with the provided attributes are going to be considered benign.
When we are in the fourth phase we can turn on the anomaly detection. This function is going to compare the running processes with the saved ones. Every time a process with an unknown name or a known process with unknown attributes is generated, our tool will raise an alert.
It can be also a good idea to generate different storages for different user roles or for different systems. For example, installing a new shell on a machine can be viable by an administrator on his own machine, but it is troublesome on a server or on an HR-related person’s machine. This detection can work the best if we are monitoring a system which rarely has new processes. This can be any workstation if company policy forbids external programme installations but the users still have admin rights. Or if the users do not have admin rights and we are afraid that they or an attacker can still install and execute softwares on the machine. Servers which rarely get new tools installed on them and the installations require change documentation could be good candidates too.
If not for alert generation this detection could be used to only store newly appearing processes. This information can still be helpful in a subsequent forensic investigation. While lots of EDR systems will provide information about the processes, a great deal of companies are still not using these tools. If storing every running process continuously can be too expensive, then storing only the new ones can be still feasible and cheap enough.
man
To read the manual of the script, please visit its github page. Since the tool is still under development I’m not going to share the instructions here. You can find the all times up-to-date version of the programme and the manual on github.