
When discussing Microsoft Sentinel data lake, the narrative centers on immediate value: cheaper ingestion, long-term storage, and historical correlation. These benefits are real, but they don’t address some interesting options.
Sentinel data lake with KQL Jobs and Notebooks transforms how SIEM data flows. Instead of direct ingestion, these tools allow data forwarding from one table to another. Cheap data lake storage enables ingestion of all raw data, while pipeline capabilities enable transformation of data after loading. This way it can replace the traditional ETL (Extract, Transform, Load) pipeline model with modern ELT (or hybrid) data pipelines. Engineers no longer have to predict what logs and fields will matter 2 years ahead - data architecture adapts as needs evolve.

This is a high-level post that explores common data architecture practices from big data platforms and how they could be used in Sentinel data lake, as the SIEM world seemingly moves toward these modern approaches.
Why Traditional SIEMs Remain Locked in ETL Architecture
ETL is the traditional SIEM pipeline approach: data is extracted, transformed (parsed, normalized, filtered), and then loaded into the SIEM. But ETL isn’t a choice - it’s a consequence of SIEM architectural constraints.
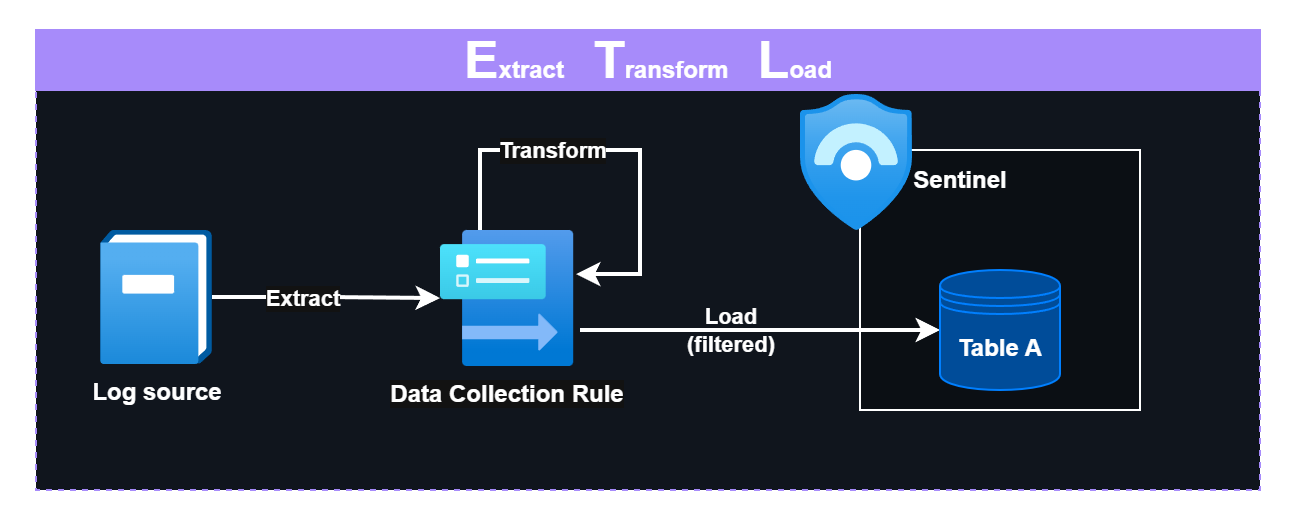 ETL ingestion pipeline in Sentinel
ETL ingestion pipeline in Sentinel
The fundamental constraints:
-
Single-tier architecture: Traditional SIEMs have one storage tier with nowhere to store raw and redundant data cheaply. You must decide upfront what to keep, making ingestion a financial decision, not a technical one.
-
Detection engines require pre-parsed data: Some SIEM detection engines only operate on already-extracted fields. If the data is not in a specified format, the engine cannot use it.
-
No post-ingestion transformation: Post-ingestion parsing and retransformation either aren’t supported by the SIEM, or they are ineffective.
Result: SIEMs become optimization puzzles where “What can we afford to see?” replaces “What do we need to see?” This blindness is problematic in a fast-evolving field - nobody can predict what data becomes essential in two years.
Sentinel data lake solves this with multi-tiered architecture capabilities. Detection-quality data flows into Sentinel SIEM while raw, untransformed data lives cheaply in the data lake as source of truth. Ingest everything, transform deliberately, detect strategically - your architecture evolves with threats instead of locking you into today’s expectations.
Sentinel data lake: Pipeline capabilities
Sentinel SIEM is fundamentally ETL-based - transformation happens before load due to high analytics ingestion costs.
Sentinel data lake’s cheaper storage and advanced pipeline capabilities enable store-first, transform-later (ELT) approaches - fundamentally different from traditional SIEM ingestion models.
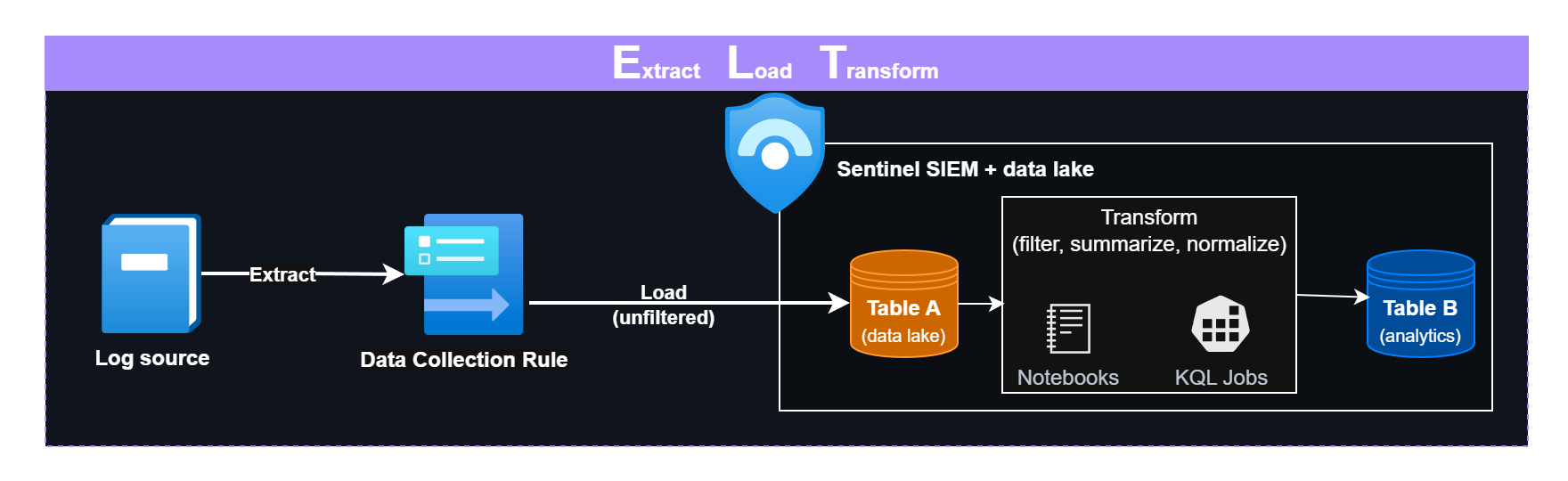 ELT pipeline with in-SIEM processing with Sentinel SIEM and data lake
ELT pipeline with in-SIEM processing with Sentinel SIEM and data lake
- Cheaper data lake storage
- Ingesting data directly into data lake is approximately 95% cheaper than analytics tier with Pay-as-you-Go pricing.
- This solves the “What can we afford to keep?” problem. You keep all logs and all fields without financial pressure to filter, eliminating the need to predict what you’ll need two years from now.
- Unparsed data ingestion into low-cost storage eliminates extraction-driven data loss. Bugs in ETL parsers (incorrect DCR transforms, DCR bugs) can permanently destroy data before it’s stored. Raw data load without DCR transformation does not have this problem.
- KQL Jobs and Notebooks: Batch processing
- KQL Jobs execute KQL queries on data lake data, enabling flexible transformation: filtering, parsing, normalizing.
- Notebooks execute Python code to process data lake data at scale, handling complex transformations beyond pure KQL. While Microsoft promotes it as a threat hunting tool for data lake, Notebooks serve as core ELT pipeline components for data parsing, enrichment, and transformation workflows - a practice refined in big data platforms like Microsoft Fabric for years.
- Both can run on a scheduled or on-demand basis, enabling you to process new data continuously (scheduled) and retroactively reprocess older data when detection strategies or threat models evolve.
These capabilities allow you to treat raw data as safe source of truth and introduce additional tables for active use. This enables multi-tiered data storage architectures like the Medallion model. In the Medallion model there are three distinct storage tiers: Bronze, Silver and Gold.
- Bronze stores raw, immutable data to act as long-term stored source of truth.
- Silver: Then the pipeline cleans, deduplicates, and normalizes Bronze data into standardized datasets in Silver.
- Gold holds curated, aggregated, enriched tables formatted for specific teams and use cases.
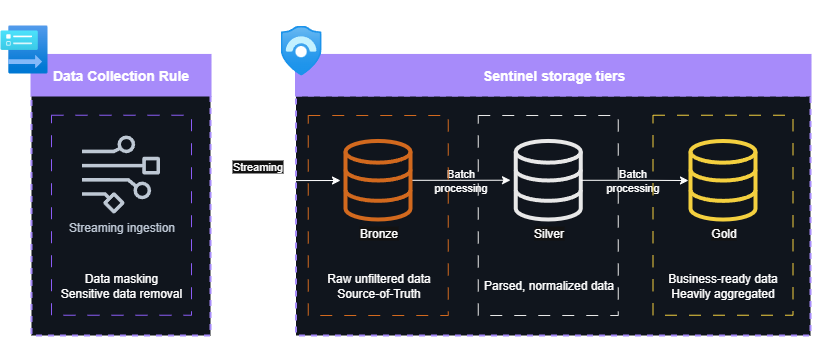 A typical multi-tiered data storage implementation
A typical multi-tiered data storage implementation
While advanced capabilities are available with data lake, it is important to note that Data Collection Rules often eliminate the need for these complex setups, enabling simpler approaches - like pushing raw data to Bronze while simultaneously ingesting normalized, filtered data directly from DCR to Silver/Gold tiers. Understanding the modern features and preparing for future needs still remains important.
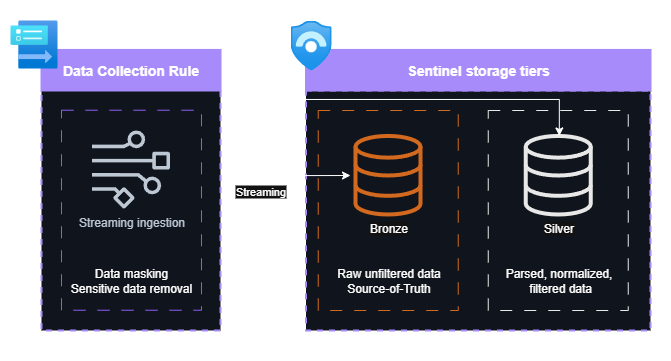 A simplified setup with direct DCR ingestion
A simplified setup with direct DCR ingestion
Multi-tiered Storage Option with Sentinel Data Lake
Unlike traditional big data platforms, SIEM best practices around tier separation are not that clear and same method cannot be applied one-to-one:
- In data platforms, Gold contains aggregated business datasets. But in security, the most aggregated outputs are detections and incidents, which don’t warrant a separate tier.
- Traditional SIEMs also serve primarily the SOC. Gold tier’s value of “different views for different audiences” has limited application when there is only one team that needs comprehensive visibility across all data.
Some practices might work in your environment, while you may need to adjust others. One organization might skip Silver-Gold separation entirely. Another might use three tiers for completely different purposes. There’s no one-size-fits-all solution.
In the next sections, we’ll explore several tier separation strategies you should consider when architecting Sentinel data lake as an advanced, multi-tiered security platform.
1. Scenario: Dual-Tiered Cost-Optimization Setup
You don’t necessarily need all three tiers. In traditional SOC environments, a dual-tiered setup frequently makes more sense. For organizations starting fresh, beginning with two tiers is often better.
Bronze Tier: Immutable Source of Truth
All logs ingest into Sentinel data lake in native format - nothing is lost to parsing errors or cost-driven discards. DCRs can still redact sensitive information without risky modifications. Bronze stores complete, unmodified data as forensic foundation and compliance archive.
Bronze is the same in every setup, so it won’t be mentioned again.
Silver Tier/Gold Tier: Operations and Detection
A single tier handles both detections and analyst queries. Data from Bronze flows through selective filtering and aggregation (via KQL Jobs or Notebooks) before being reingested into analytics tier for real-time detection and SOC analysis.
Parse based on detection requirements: forward parsed logs for cost savings if detections accept this format, or raw events if they don’t.
This parsed, filtered, and summarized data is typically sufficient for SOC investigations. In rare cases, teams access Bronze logs for additional context. Other teams, such as Threat Hunt or Forensics, might access the Bronze tier more frequently.
This is a similar usage model to what Microsoft suggest but with KQL Job and Notebook-based pipelines as addition.
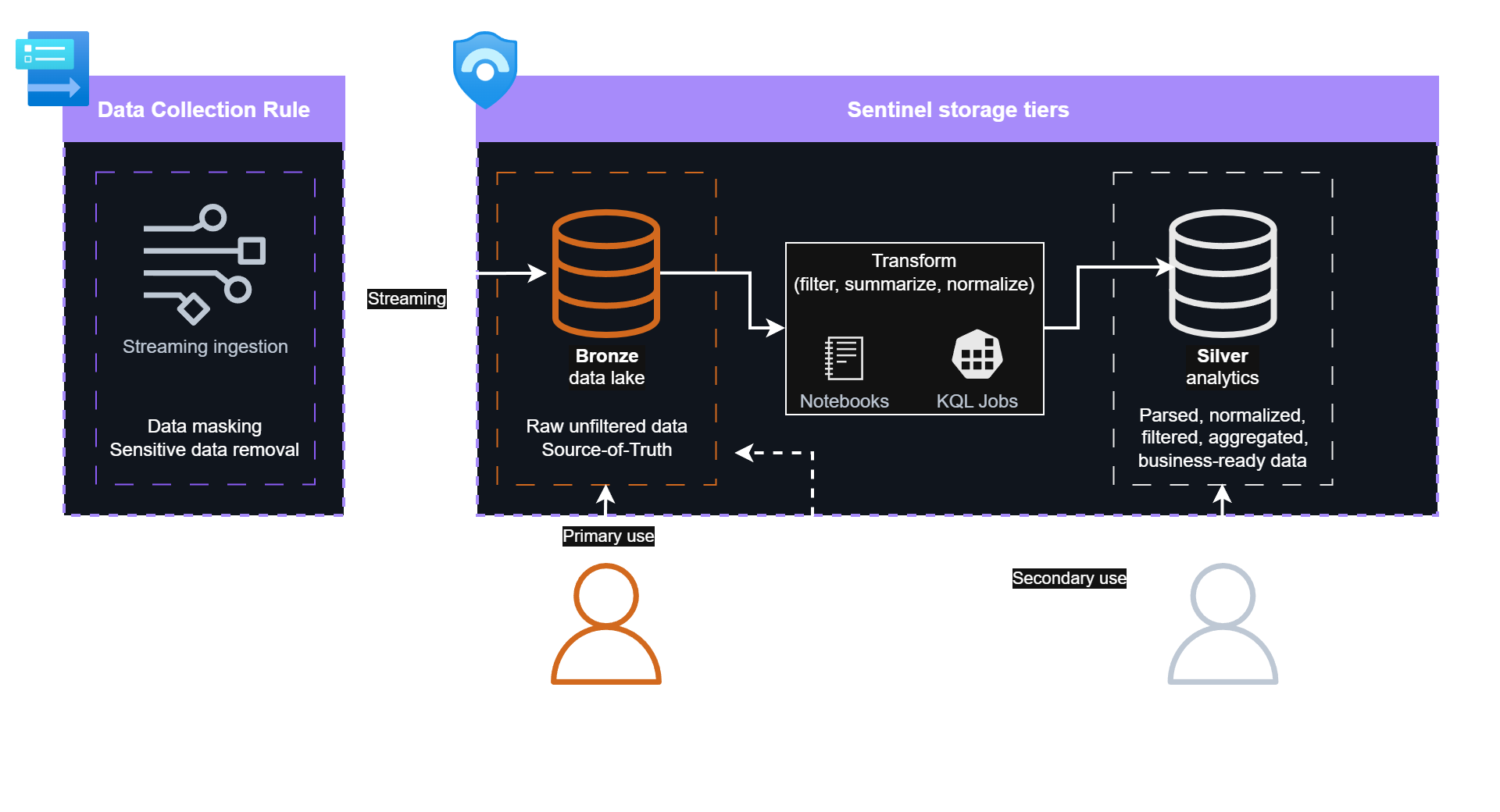 SOC analysts relying on the detection-ready analytics data, while other teams using data lake logs in this scenario
SOC analysts relying on the detection-ready analytics data, while other teams using data lake logs in this scenario
Summary
| Medallion Tier | Table Tier | Primary Users | Secondary Users | Retention | Cost Elements |
|---|---|---|---|---|---|
| Bronze | Data lake | - transformation pipelines - traditional machine learning |
- dfir - threat hunt - compliance |
- Maximum required | - Full ingestion - Maximum retention (All data) - Data usage |
| Silver/Gold | Analytics | - detections - security teams (SOC, DFIR, threat hunt) |
- | - Maximum required | - Filtered ingestion - Maximum retention (Filtered data) |
Data retention costs in Sentinel data lake assume 6x compression, making long-term storage 6x cheaper than before data lake was available. Even if you store data twice in the two tiers, you achieve 3x+ cost savings versus pre-data lake architectures. For most organizations, data retention is a negligible cost element. You can calculate yours with my data lake cost calculator.
Setting both tiers to ‘Maximum required’ retention is often better from a management perspective with minimal cost impact. You can still configure different retention policies for individual tables within each tier if needed.
This is a good option if:
- You prefer a more traditional setup that can be easily extended in the future
- Your aggregation/summarization serves other teams effectively - heavily summarized data may not fit all team workflows
- Bronze tier contains raw, unoptimized events, so this approach is ideal when teams only occasionally need to query billable Bronze data - infrequent DFIR or threat hunting exercises
2. Scenario: Full Three-Tiered with Dual Data Lake
This three-tier approach separates concerns: Silver stores parsed, normalized data in data lake without filtering or aggregation - this balances cost and efficiency. While Gold contains filtered, aggregated data in Analytics tier for real-time operations.
Silver tier ingestion to data lake is cheap enough that aggressive filtering isn’t necessary, yet storing parsed, deduplicated data in dedicated tables (like data model-based structures) makes subsequent queries more efficient - directly reducing query costs for further parsing or manual investigation.
Silver Tier: Optimized Supporting Tables
Fully parsed, deduplicated data without filtering or aggregation optimized for efficient further processing and occasional queries. When looking for data not found in Gold tier teams don’t have to rely on the inefficient Bronze tier, they can rely on this low cost, query efficient data set. Because it is not filtered, it can satisfy most needs.
Organize logs into dedicated Silver tables by data model or log source for efficiency, but ensure you can generate Gold tier data from these specialized Silver tables for detection rules to process.
Since Bronze retains all data long-term (Maximum required), Silver can apply shorter retention policies if retention costs matter. Typically unnecessary given the low cost of retention, but an option if needed.
Gold Tier: Operations and Detection
Heavily Aggregated, filtered data optimized for fast real-time querying, detections and investigation. Only for detection and SOC-related logs.
If Silver uses shorter retention, keep Gold at ‘Maximum required’. Otherwise, apply selective retentions, so ‘Maximum required’ to critical data only - such as alerts and incidents.
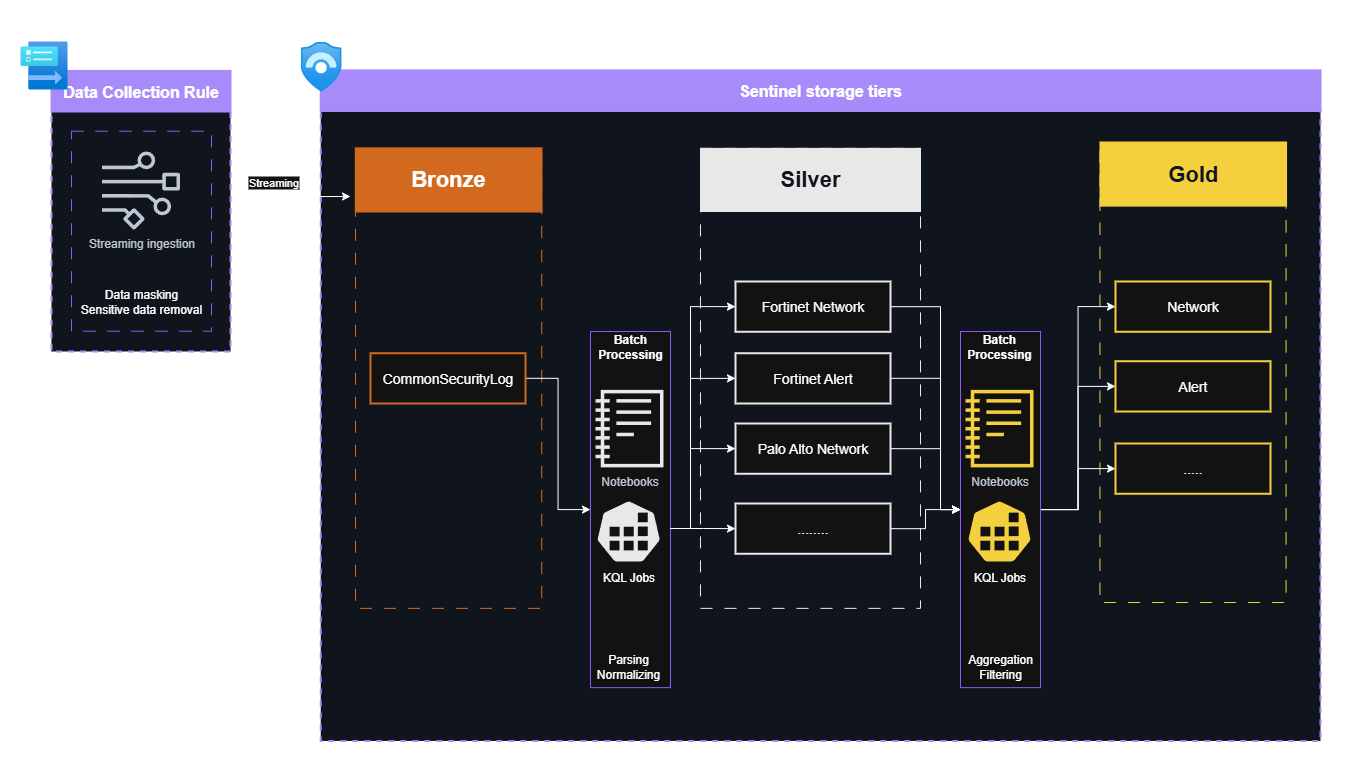 A possible implementation of this scenario
A possible implementation of this scenario
Summary
This hybrid approach is effective when heavy filtering means SOC teams occasionally query Silver tier for investigation detail, while threat hunters access older Silver data cost-efficiently without querying raw Bronze datasets.
Forward less data to Analytics tier (Gold) since Silver provides efficient data lake lookups. So unlike in the previous scenario, here querying Bronze tier manually is avoidable. This reduces both Analytics ingestion and Data query/Advanced Data Insights charges.
However, it increases data lake ingestion and retention costs, because we store similar data both in Bronze (raw) and Silver (parsed). Typically, the cost benefits of more aggressive filtering and aggregation in analytics tables outweigh the costs from additional data lake ingestion and retention; however, this depends on your specific requirements.
| Medallion Tier | Table Tier | Primary Users | Secondary Users | Retention | Cost elements |
|---|---|---|---|---|---|
| Bronze | Data lake | - transformation pipelines - traditional machine learning |
- compliance | - Maximum required | - Full ingestion - Maximum retention (All data) - Data usage |
| Silver | Data lake | - transformation pipelines - LLM AI usage - DFIR - threat hunt |
- SOC | - Based on typical usage OR - Maximum required |
- Parsed ingestion - Maximum retention (Parsed data) - Data usage |
| Gold | Analytics | - SOC - other non-security teams |
- threat hunt | - Maximum required OR - Critical data: Maximum required - Other data: 90days |
- Filtered ingestion - Maximum or per-table retention (Filtered data) |
This is a good option if:
- You expect frequent queries on the data lake - Silver tier is optimized for this
- Agressive filtering of analytics data is possible while keeping most investigations in the Gold tier - this requires a solid understanding of your teams, processes, and a well-documented mature data model
Best Approach
Each scenario differs subtly - consider the one matching your team’s workflow: lookback windows, data needs, and historical data access frequency. You don’t need complex pipelines immediately, but having team members who understand data architecture helps as Sentinel evolves.
Sentinel data lake is still improving with new features coming from Microsoft. Limitations you face today may disappear in the coming months, so revisit your design choices as the platform matures.
Sentinel Data Collection Rules handle filtering and transformations at ingestion, often eliminating the need for complex pipelines. For most, ingesting all raw data to Bronze tier while directly sending filtered data from the DCR to your Silver/Gold is usually good enough.
Use DCRs when the following conditions apply:
- Logs need immediate availability without pipeline delays
- Filtering and transformations are straightforward (DCRs have limited capabilities compared to KQL Jobs)
- Data aggregation is not required (DCRs process events individually, no summarization)
For heavy parsing, complex logic, or summarization, KQL Jobs and Notebooks are necessary, but for many teams, DCR filtering is sufficient and faster.
Limitations of KQL Jobs and Notebooks
Both tools have practical limitations:
- Processing delay: Added latency versus DCR-based ingestion filtering
- Data lake table usage: Both KQL Jobs and Notebooks can only create analytics tables by default - workaround requires creating analytics tables first, then converting them to data lake type
- Default table restrictions: Can’t write directly to default tables, requiring detection modifications
- Stability issues: Recent bugs have affected both tools, so test thoroughly before production deployment
- Data safety: Custom tables created by KQL Jobs and Notebooks lack protections against removal - deletion is permanent, unlike standard tables which have brief recovery windows
- Concurrency limit: There is a strict limit on how many KQL Jobs / Notebooks can run simultaneously, causing additional ones to be queued - adding complexity and delay
Start simple with DCRs and Bronze tier. Use your Bronze tier as source of truth. As your team matures and understands your data patterns, gradually introduce pipelines and additional tiers. Sentinel data lake’s flexibility means your architecture can evolve without costly rework.