
When selecting a new security technology, cost is a crucial factor. It does not matter how effective a tool may be, it becomes irrelevant if it’s unaffordable for you. As a result, it is critical to have someone who is experienced with the solution to prevent overpayment and maximize your investment.

Expert assistance is crucial when considering a Security Information and Event Management (SIEM) solution. SIEMs often come with varying licensing models and can be quite costly. Understanding the specific SIEM tool in use, along with its ability to utilize different event types with various effectiveness, can lead to significant cost savings
Cost reduction through log design in Sentinel
In Sentinel, the main cost is based on the size of your data. This means you have to decide not only which log source types or event types to collect but also what information to keep in the events. By selectively retaining essential information and dropping unnecessary events or fields, you can manage costs while maintaining visibility.
When designing your logging setup, it is essential to make informed decisions that strike a balance between cost considerations and the level of visibility you aim to achieve in your SIEM. When deciding on which logs to collect in Sentinel, consider the following factors :
- Log Source Type Selection: Evaluate the value and cost associated with each log source type to determine its relevance to your SIEM. Focus on onboarding log sources that provide significant security value while being mindful of the associated costs. For instance, prioritize firewall events over less critical logs like switch or router logs.
- Selective Device (log source) Onboarding: Optimize costs by selectively choosing which devices to collect logs from within the valuable log source types. Focus on logs from key devices such as perimeter firewalls over less critical internal firewalls or non-essential traffic logs, ensuring efficient data collection. Always take into account both the value and the cost aspect of a log.
- Event Type Filtering: Tailor your log collection strategy by filtering out less critical event types. Configure your devices to forward specific logs or use ingestion-time transformation in Sentinel to filter out unwanted event types, such as collecting ‘Allow’ firewall logs while omitting ‘Deny’ logs for more focused monitoring. Or dropping traffic of less important protocols.
- Field Relevance: Identify and retain fields that are essential for security purposes while omitting redundant or non-security-related fields to streamline data management and minimize unnecessary information. By dropping redundant fields, you can reduce the cost without causing any information loss.
You may encounter events and fields that are non-redundant when considered individually, but they can become redundant when combined with other information. For example, a firewall log might include an IP address along with information about whether that IP is owned by your company. This event alone does not have redundant information. However, if your SIEM also has a table listing the subnets owned by your company, the ownership information in the firewall log would be unnecessary.
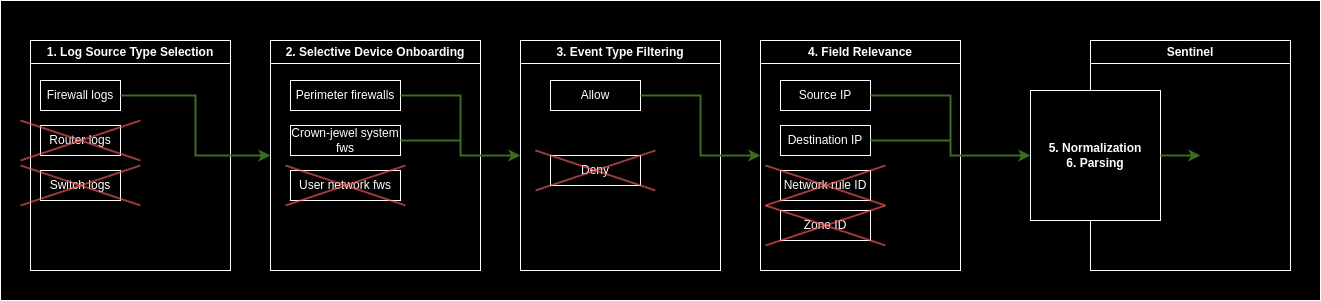
- Normalization: Normalize data by standardizing field names and content formats to align with your data model, optimizing data storage and retrieval efficiency. This step can both increase and decrease the size of your logs depending on your data model and your raw data. For example, in firewalls you can store the network protocol information with a number or with a string. The number of the ‘tcp’ protocol is ‘6’. Depending on what you have and what you need you can increase the size of the information from 1 byte to 3 bytes or decrease it from 3 bytes to 1.
- Parsing Efficiency: Enhance data processing efficiency and decrease the effective log size by parsing logs into structured formats. Extract relevant information from unparsed or partially parsed fields to improve data organization and reduce storage overhead, optimizing cost-effectiveness in log management. By extracting the values you can get rid of field names, key-value and pair separators in the logs (see examples below).
Parsing vs Normalization: In this article, I refer to ‘parsing’ as the process of extracting valuable data from one field and transferring it to another field. On the other hand, when I mention ’normalization,’ I am describing the act of altering the field name or data content and format to conform to a standardized data model. Sometimes the two steps appear inseperable and the parsing of data frequently involves an inherent normalization process.
In Sentinel, you have the capability to develop highly efficient query-time parsers. This allows you to extract and parse logs for cost-effective storage and then create query-time parsers to normalize the data in alignment with your preferred data model. In this manner, normalization will not restrict your cost-saving initiatives.
Preservation of information:
- Data loss: From the aforementioned list, items 1, 2, and 3 usually lead to data loss. In essence, if you do not onboard a log source, device, or event type, it will not be present in the SIEM.
- Potential data loss: Item 4 can be either lossless or lossy, depending on whether redundant data (which many logs contain) is discarded.
- Lossless: Items 5 and 6 typically result in complete losslessness, as these steps involve altering the location and format of information in the logs.
Cost-effectiveness through parsing in Sentinel
It is straightforward that not onboarding or dropping specific logs and data can save a lot of money, and a lot of companies are heavily relying on these methods to decrease the cost of their Sentinel instances.
While the concept of decreasing log size through parsing is a logical step and offers a lossless cost-saving opportunity, it is often underutilized. In most environments – and I have worked on more than 100 Sentinel instances – the lack of proper ingestion-time parsing implementation hinders cost-saving benefits.
The reluctance to use data extraction efficiently can be attributed to two main factors, primarily stemming from the novelty of ingestion-time transformation and Data Collection Rule (DCR) functionalities in Sentinel:
- Lack of Expertise: There are a lot of things one can do with DCRs and ingestion-time filtering, but most of the people and companies are just scratching the surface. Safely extracting data, creating new fields, and ensuring data integrity during ingestion require expertise to avoid data loss and maintain accuracy. Also, in some case, parsing needs to be done within the connector code, and many companies are hesitant to modify the connectors or develop their own.
- Legacy Code Challenges: Existing rules and query-time parsers in Sentinel often rely on the raw, unchanged data, making data extraction and field manipulation difficult to manage. Shifting data from one field to another can render established codes ineffective. To accommodate changes in log format and schema, adjustments to rules and parsers are necessary. Additionally, monitoring alterations in the format introduced by the log source vendor is essential to ensure seamless data processing.
Despite the potential for significant cost savings without data loss, the underutilization of parsing capabilities persists in many environments. A lack of awareness regarding the financial benefits of proper parsing techniques, along with the required technical effort in some cases, often leads to missed opportunities to optimize cost efficiency in log management.
Examples of common parsing inefficiencies
Check the following 4 examples for potential optimization ideas through parsing to achieve substantial cost savings.
1. Fortinet firewall logs
Explore the following sample logs for potential optimization through parsing to achieve substantial cost savings.
The non-CEF formatted log looks like this:
date=2018-12-27 time=11:07:55 logid="0000000013" type="traffic"
subtype="forward" level="notice" vd="vdom1" eventtime=1545937675
srcip=10.1.100.11 srcport=54190 srcintf="port12" srcintfrole="undefined"
dstip=52.53.140.235 dstport=443 dstintf="port11" dstintfrole="undefined"
poluuid="c2d460aa-fe6f-51e8-9505-41b5117dfdd4" sessionid=402 proto=6
action="close" policyid=1 policytype="policy" service="HTTPS"
dstcountry="United States" srccountry="Reserved" trandisp="snat"
transip=172.16.200.1 transport=54190 appid=40568 app="HTTPS.BROWSER"
appcat="Web.Client" apprisk="medium" applist="g-default" duration=2
sentbyte=3652 rcvdbyte=146668 sentpkt=58 rcvdpkt=105 utmaction="allow"
countapp=2 utmref=65532-56 If this data arrives into the Syslog table and all the information is stored in the SyslogMessage field, then the log will be huge. The impact of overhead becomes evident in certain instances. For example, analyzing the “proto=6” field reveals the following breakdown:
- 5 bytes for the field name (proto)
- 1 byte for the key-value separator (=)
- 1 byte for the value (6)
- 1 byte pair separator (separates 2 key-value pairs; a space character in this case)
By parsing this value into a new Protocol field, you eliminate 5 bytes for the field name, 1 byte for the key-value separator, and 1 byte for the pair separator, reducing the content from 8 bytes to just 1 byte, marking an 87.5% decrease in size.
In the case of the 705-character long Fortinet log above, removing field names, key-value separators, pair separators, and double-quotes results in a 266-character string, reflecting a 62% reduction in the field’s size.
2. Palo Alto CEF logs
The situation is similar with Palo Alto logs. One notable distinction is that the commonly used PA fields typically have shorter names, resulting in lower overhead. However, upon examining certain field names, it is clear that they can still be quite lengthy:

When working with Palo Alto logs, you have the option to configure your device to exclude specific ‘fields’ from being forwarded. Additionally, you can rename fields to shorten them and avoid excessive field name length. As depicted in the image, many field names are quite descriptive and often include the useless ‘Pan’ or ‘PanOS’ strings. Another approach is to extract these values into new individual fields for better organization and clarity.
Typically, it is recommended not to alter the format of standard tables such as the Syslog or CommonSecurityLog table. Therefore, if you encounter unparsed logs within these tables, it may be more practical to forward the logs to custom tables instead and parse them there. But the possibility is always there to just add custom fields to these tables if needed.
I ran a quick size decrease calculation based on a sample log from this Palo Alto link:
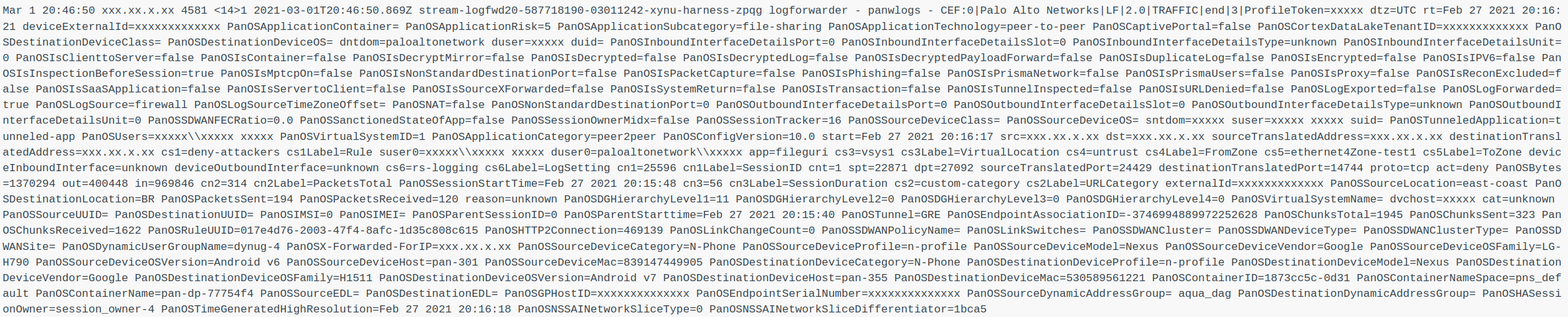
The length of the log following the CEF header is 4445 characters. Notably, certain fields within this log example are empty, meaning that the extensive field names in the log represent an unnecessary consumption of both data and money. Upon eliminating the field names, key-value separators, and pair separators, we are left with a string that is 1145 characters in length. This is a 74% reduction in size.
Sentinel has the capability to automatically parse certain fields when dealing with CEF formatted logs, reducing the need for manual parsing of every bit of information.
3. Azure Diagnostic settings legacy and new logging
The AzureDiagnostics table is a really good example of how putting different logs into one table in a semi-parsed way can affect the logging and monitoring environment. When Microsoft introduced the Diagnostic Settings for Azure Resources for monitoring purposes all the logs (at least most of them) were forwarded into the AzureDiagnostics table.
Consequently, the AzureDiagnostics table housed logs from various sources like Key Vaults, Storage Accounts, and Firewalls. While numerous logs were parsed into distinct fields, certain logs stored a significant amount of data in the ‘RawData’ field in an unparsed manner.
Microsoft has since transitioned from this approach, assigning many resources their dedicated tables. This shift ensures that each table contains logs specific to a particular resource type, enhancing parsing efficiency and minimizing the storage of large semi-parsed logs.
For Azure firewall logs (as an example) Microsoft states:
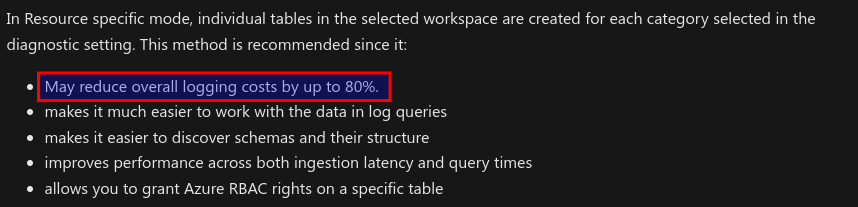
When incorporating these logs today, leveraging resource-specific tables is the recommended approach.
4. JSON data
Sentinel has native capabilities for processing JSON data and parsing it into fields. However, handling JSON objects within an array is a challenge for the SIEM. This limitation is not surprising because removing an array requires a thorough understanding of the schema of the logs and sometimes it is not even feasible.
There are two common scenarios where manual elimination of arrays is possible. Nevertheless, caution must be exercised to prevent data loss due to a potential format change:
- When an array consists of a single JSON object, the array can be eliminated. This situation may occur when a vendor initially used an array to allow flexibility but later did not utilize it as such. It is crucial to ensure that if the vendor decides to use the field as an array in the future (containing more than one object), data loss is not happening.
- When the objects within the array have a pattern that facilitates the creation of unique fields (refer to the example below).
There are other scenarios as well, but most of the time in these situations, eliminating the array is a design mistake that can cause issues later on. Therefore, caution is advised.
An example for the second case is a mock EDR detection event below:
{
"source": "EDR",
"description": "Brute-force attempt",
"entities": [
{
"type": "user",
"entity": [
"userA",
"userB"
]
},
{
"type": "machine",
"entity": [
"ComputerA"
]
}
]
} In Sentinel, the log will be formatted as follows:
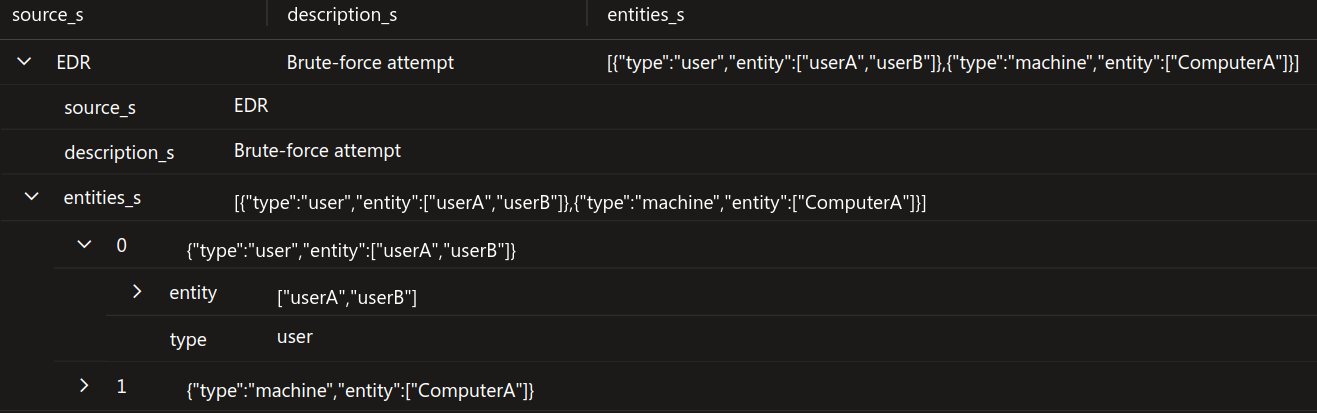
Upon examining the image, it is evident that the entities_s field contains significant overhead due to the inability to parse objects within the array. To address this issue in your connector, you should implement a mechanism to extract the fields. This process will result in an empty entities_s field, along with two new fields: entities_user with the value ‘[“userA”,”userB”]’ and entities_machine with the value ‘[“ComputerA”]’.

By transitioning from the original format – [{“type”:“user”,“entity”:[“userA”,“userB”]},{“type”:“machine”,“entity”:[“ComputerA”]}] (86 characters) – to the optimized format [”userA”,”userB”] and [”ComputerA”] (30 characters), significant space savings can be achieved. The uniqueness of the type field enables this transformation. This resulted in a 65% decrease in the length of that field.
If you are utilizing a Python-based data connector for processing these JSON events, extracting the fields, even unknown ones, can be easily accomplished.
There are some other metadata fields in the logs as well not visible in the picture.
It is more advantageous to perform the parsing of JSON logs within the connector code rather than during ingestion-time transformation. This approach offers greater flexibility and improved error and exemption handling capabilities.
End of Story
I have collaborated with companies that opted to collect only a subset of logs to significantly reduce ingestion volumes. Similarly, individuals have chosen to forward only specific fields to achieve the same cost saving.
But many neglected to parse these logs, missing out on a potential 60% reduction in costs for the same log type. While parsing demands additional effort, it offers a lossless solution.
In the event of a breach, investing more effort to reduce the cost in a lossless manner can prove beneficial. Having the information available when required, instead of missing it due to (unnecessary) cost saving measures, can be crucial during an investigation. I recommend assessing your noisy log sources and prioritizing the parsing of at least the low hangig fruits.